
TL;DR: When confronted with challenging wireless networks, traditional CDNs bring limited performance benefits for mobile users, and more often than not, the user experience gets compromised. To fix this, we explore the new concept of Mobile CDNs, the first objective approach to an old problem - Delivering content to mobile devices without getting user experience destroyed by wireless instability. In this article, we will navigate through our journey from why we are building a Mobile CDN, to how we are deploying it.
The app, the user, and the experience
You are a proud product owner. You have prepared everything so that your app is flawless, with the best user experience. You took the time to optimize most aspects of your app and deployed a CDN to ensure that your users can get the content out of the gate. All the items in your user experience checklist are ticked. You set out to test your app, and everything seems perfect. In your office and your house, the app’s performance and the user experience are top-notch. You feel confident.
So confident that you decide to expand your tests. You go for that coffee at your favorite place and test the app again. Your confidence gets a bit shattered. This time, the app feels a bit sluggish, and that perfect experience is no longer there. You see the loading spinner often, and content takes longer to get shown. Getting back to the office, you sit down and look at your metrics dashboard and confirm what your feeling indicated. Performance is not as good as you’ve expected.
You’ve done everything right, followed the textbook optimizations, and yet, you no longer feel confident that every user is getting the experience you were striving for. Why?
The (same old) problem
You already knew that the location of users could have a significant impact on performance. That is precisely the reason why you have already deployed a CDN in the first place. You want your content to be served from a location as close to the user as possible, reducing the impact of latency when serving the content. So, why are you still experiencing performance degradation? Because the issue is more complicated than just the user location: the user’s network also presents a massive impact on your app’s performance.
The last mile, the most challenging mile
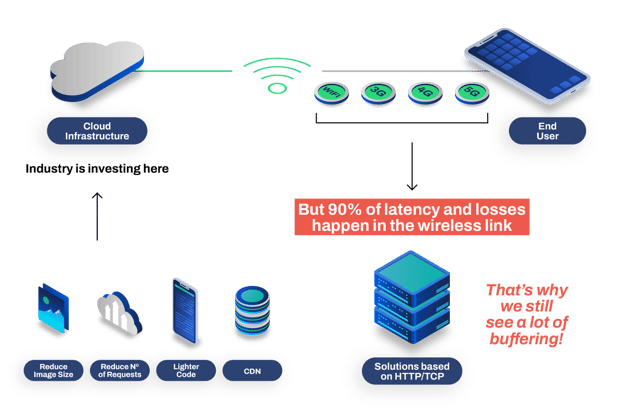
You are probably thinking, aren’t CDNs the ultimate solution to overcome reducing load times and increasing responsiveness? Short answer: no!
Ultimately, a CDN brings copies of your content to multiple edge locations spread around the globe. If your origin content is stored in a single location or your customers have high latencies to your servers, then this strategy will surely bring some benefits for your app. You also take advantage of other CDN benefits, such as improved scaling capabilities during heavy traffic demand and decreased infrastructure costs due to traffic offloading, which is achieved by caching content in the edge. But none of those capabilities manage to have an impact over the most significant challenge, the wireless last mile. By placing content on the edge of the Internet, CDNs overcome the challenges of the first mile and the middle mile. However, 90% of bad user experience is caused by issues in the wireless link (e.g. WiFi, 3G, 4G, or even the upcoming 5G), namely wireless instability. By being at the edge, CDNs by themselves do not solve the problem. Imagine we could place a CDN PoP at every telco tower or every WiFi access point. Even in this best-case scenario, CDNs would not be able to overcome the wireless last mile instability.
Users can be part of the solution
So, why do traditional CDNs not solve the problem of wireless instability? Because they rely on HTTP and TCP to deliver data to clients. TCP was built in the 70s for the wired world and does not take into account the challenges and dynamics of wireless environments. Thus, TCP performance suffers in the presence of latency, jitter, and other instability factors, which are very common in wireless environments.
So, let’s improve TCP, right? Not so fast. Even though upgrading TCP on the server side is relatively easy to achieve, the same cannot be said for the client side. TCP is built-in to the kernel of our client devices. To update it, we would need to update every single device’s kernel in the market. An impossible task.
We need a new approach to solve this problem. We need to bring new protocols that are aware of wireless environments’ challenges and capable of performing, even under those conditions. And we need to be able to run these new protocols on the client side. In other words, the client needs to be part of the solution.
A new protocol? Are we crazy? Yes, we are! But not to that extent. Over the last couple of years, some transmission protocols have appeared on the scene. One of the most famous is QUIC, which is the backbone of HTTP/3, after a considerable standardization effort led by IETF. Initially developed by Google, QUIC is a UDP-based protocol that aims to improve the performance of TCP. By being UDP-based, it allows true 1-RTT connection establishment and 0-RTT connection re-establishment, provides better packet sequencing, improved loss detection mechanisms, and native multiplexing (thus eliminating head-of-line blocking issues). But one of the essential features of QUIC is that it is deployed in user-space. However, even with these improvements, QUIC still relies on old mechanisms to perform flow control, rate control, and loss recovery, which impairs its capabilities to deliver improved performance over the one achieved when compared with TCP.
To truly solve the challenges of wireless instability, we at Codavel have developed a new protocol, Bolina. Based on Network Coding techniques and by being UDP-based, Bolina introduces a new flow control, new rate control, and a unique coded-based loss recovery mechanism. Bolina was built from the ground up to address the issues and challenges that wireless networks and their instability pose to mobile applications.
How do we deploy it?
With our Bolina protocol, mobile applications can provide an exceptional user experience for any client, independent of its location, device, or network. So, what is the best way to allow our customers to take advantage of Bolina? With its unique flow control and rate control, Bolina is more resilient to network latency, and with that, we at Codavel could deploy a set of servers in a limited number of locations. However, Bolina can benefit from reduced latencies, allowing the protocol to become more reactive to adverse network conditions. The only missing piece was a way to deliver all those benefits to the public, and that's why we decided to develop an SDK to enable mobile applications to integrate Bolina directly into their lifecycle.
On top of the mobile SDK, we decided to create a Mobile CDN, which leverages Bolina to achieve improved performance. In a way, we are delivering a next-generation CDN, where besides all CDN benefits, we also provide the benefit of a tailor-made protocol for wireless environments, enabling users to achieve top-notch user experience and allowing our customers to open or capitalize from newer and until now, out of reach markets.
Building a CDN
So, let’s build a CDN! One of the first needs of a CDN is to be in as many points-of-presence (PoP) as possible. As with traditional CDNs, multiple and vast PoPs allow Codavel CDN to ensure reduced latency, thus maximizing and overcoming the challenges posed by the first and middle mile and improving upon various challenges that some countries faced in the Internet exchange connection points. In the perfect world, we would like to have a PoP in every big metropolitan area of the world. However, that is a massive challenge for every company, especially for a small tech startup.
To overcome these challenges and speed up the deployment process, we have decided to leverage the computational power and availability of cloud providers. Easy right? Not so fast. First, cloud providers have a limited presence around the world. For example, at the time of this writing, Azure provides 43 PoPs, while AWS only provides 23 PoPs. These values are shy compared to those offered by other traditional CDN providers, such as Akamai or CloudFlare. Nevertheless, if these PoPs were spread unbiased worldwide, a single cloud provider could be a great candidate. However, that is not the case. For example, Azure and AWS have a strong presence in central Europe, Asia-Pacific, and at each US coast. However, they lack present or present a weak presence in many regions, such as South America, Africa, and India.
So an obvious solution is to leverage multiple cloud providers to improve our PoPs. But, how can we deploy a CDN service throughout numerous cloud providers without facing deployment nightmares?
Kubernetes to the rescue
That’s right. We make use of Kubernetes (you can learn how it began here). Kubernetes allows the containerization of service and is one of the best ways to deploy, scale, and manage such services automatically and efficiently. Kubernetes is a powerful tool. However, it lacks one feature, horizontal scaling. Kubernetes by itself is not capable of communicating with a specific cloud provider and asking it to add new VMs to its cluster.
To overcome such limitations, nowadays, basically, all cloud providers provide a Kubernetes engine as a service, meaning that they manage all pieces for you, while you only need to worry about your service requirements, including the horizontal scaling. And this was the way we decided to start using Kubernetes by leveraging AWS Managed Kubernetes Engine (EKS). With AWS EKS, we ensured that all our CDN components could scale, get discovered, and communicate with each other. Meanwhile, AWS EKS would constantly monitor our cluster deployment, deploy new VMs and add them to the Kubernetes cluster so that the Kubernetes engine could deploy new nodes and containers. And it worked great!
The next step was to redeploy our service, but this time, in Google’s Kubernetes Engine (GKE). And our fears became a reality. GKE feature set is not 100% equal to AWS EKS. Also, to use it, we would need to customize our EKS Kubernetes deployment configuration to GKE. And this was also going to be true for Azure’s Kubernetes Service (AKS), the following cloud provider in the pipeline. We needed a new approach to create a single Kubernetes configuration and deploy it everywhere, without significant rewrites.
Rancher to rule them all
Rancher, in a nutshell, allows the management of Kubernetes deployments in basically any environment. Rancher takes care of the horizontal scaling (creation or destruction of new VMs) by orchestrating the VMs lifecycle directly with the cloud provider via their APIs, while Kubernetes takes care of all other features. This way, we can have a single Kubernetes deployment configuration and deploy it on AWS, Azure, or Google Cloud. As a bonus, we manage these different and distinct deployments via a unified interface and can deploy a new cluster in a manner of minutes, compared to the hours it used to take.
Geo-DNS has the map
Now, if you are a CDN architecture engineer, you may be wondering, how do we know where to send the users’ traffic? In a nutshell, we rely on Geo-DNS, DNS resolution that considers the users’ location, and with it, we can ensure that end-user traffic is forwarded to the closest PoP. With this approach, plus the multiple cloud providers we use, we could not leverage traditional DNS services like AWS Route53. These DNS services provided by the major cloud providers are, in a way, dumb. They do not know which regions exist in the globe besides the ones that the cloud providers use. For example, AWS Route53 can only see a single PoP in India, and if we rely on it, we would not be able to forward traffic to our 6 PoPs in India. The solution is to leverage a third-party Geo-DNS service such as Constellix. With Constellix, we can deliver traffic to any specific location in the world based on the end-user location.
Let’s wrap it up
To summarize, we leverage Rancher to deploy Kubernetes clusters in multiple cloud providers to provide a solid global presence. With this approach and relying on AWS, Azure, GCP, DigitalOcean, and Linode, we are present with 71 PoPs spread around the globe. We are actively looking into expanding our presence even further.
Beyond the core
Having detailed how we deploy our Mobile CDN around the world, let’s discuss a bit about how we try to ensure a zero-downtime service.
Each of our Mobile CDN service deployment is composed of three major components: the load balancer, the Bolina engine, and the cache engine. Each of these components is configured to scale independently from each other. For example, Kubernetes will deploy new nodes and containers and allocate them to the cache engine if the cache engine needs more resources. This way, the cluster can adapt to all traffic needs and behaviors. Also, besides the typical Kubernetes resource management, such as CPU and memory, we continuously monitor the communication latency between all components and order the cluster to scale to minimize this latency.
Moreover, given that all distinct CDN deployments are managed by Rancher, in case a cloud provider becomes unavailable in a specific region, our Mobile CDN is capable of rewrite the Geo-DNS policy and redirecting the end-users traffic to an alternative PoP, which as we have discussed, can be hosted in other cloud providers.
All these measures are employed in the Mobile CDN service side. Given that we are also present on the user side, our service can make intelligent decisions as well. In the event of a complete cloud failure, the SDK, placed on the user side, can understand that the service is not responding and will fallback all requests and traffic to another endpoint. This way, the mobile app service will not stop, and the end-user will never stop engaging with it.
|
Traditional CDNs |
Codavel Mobile CDN |
|
|
Reduce latency of end-users |
✅ |
✅ |
|
Acceleration from origin to edge |
✅ |
✅ |
|
Acceleration from edge to user |
❌ |
✅ |
|
Optimized for wireless connections |
❌ |
✅ |
|
End-to-end performance visibility |
❌ |
✅ |
|
Resilience to cloud/infrastructure provider failure |
❌ |
✅ |






