
tl;dr: Network coding is awesome! Let’s build a better Internet!
What is network coding?
If somehow you’ve reached this blog post, I’m assuming you want to learn more about network performance and are interested in elegant communication protocols. This particular post is focused on network coding, a groundbreaking mechanism that enables efficient and reliable communication over data networks.
Let’s get ready then!
Welcome to “The Internet”
Since the birth of the first communication networks (ARPANET, Internet, ALOHAnet, ...), network engineers have worked relentlessly to provide reliable, efficient, and fast communication networks. We have now access to gigabit ethernet links and WiFi/mobile connections are blazingly fast, reaching hundreds of megabits per second. At least in theory.
Even today, it’s not uncommon for us to experience the frustration of waiting for an app to fully load its content or having video calls with frozen screens and poor audio quality. And why does this happen? The answer is fairly simple. While the advances we’ve seen in the last decades are impressive, so is the growth of network usage, in particular over wireless networks.
Have you noticed how many devices are using your home or office network connection? Well, probably a lot...
And guess what? All of them are using a portion of your home bandwidth. All of them are also using a portion of your ISP’s bandwidth. Probably most of them are also using a wireless connection, meaning they will face the challenges of latency, jitter and packet loss. Given all of these facts, it’s not that surprising that we face many situations where network performance is far from ideal (or its theoretical promises).
The data path
To lay the ground for this post, let me first introduce the basic data flow over a communication network (feel free to skip to the next section if this seems too introductory).
When two nodes wish to communicate over a network path (say your typical client-server application), the requests (in the form of data packets) from your application are sent to your wireless router, which then sends them to your ISPs network, which on their turn sends them to a core network, which then forwards them to the appropriate server that should handle your request (I do apologize for the oversimplification).
At all these points, network components (routers and switches) operate in a store-and-forward way. They have a buffer which they use to store the received packets to then send them to the next hop in the data path. If too much bandwidth is being used, these buffers fill up, adding latency and packet loss to the connection (along with the intrinsic latency and packet of the communication path). If the client’s first hop is a wireless connection, the situation is even worse, due to its characteristics (added latency due to MAC contention and packet loss due to interference and signal propagation issues...).
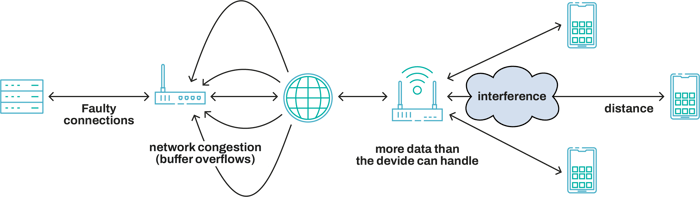
So, by now it should be clear, if I was the only guy using the Internet, things would be great! (apart from being the only guy on Twitter which would probably suck). I would send/receive my packets at a nice rate, devices could store-and-forward them without any errors (as long as my sending/receiving rate would not surpass the underlying end-to-end bandwidth).
However the reality is very different from this - there is a lot of competition for bandwidth, which ends up creating undesired effects on the network such as packet loss and latency. Now, I’m sure you’re wondering, can we do better at scaling network communications? Turns out we can.
Network coding “back-to-basics”
Network coding was firstly described at the turn of the century (funny coincidence huh?), by Ashlwede, Cai, Li and Yeung, in their revolutionary work about network information flows. What they showed was essentiallly that traditional store-and-forward routing strategies were not necessarily optimal from a capacity point of view.
This was easily illustrated by the (now) well-known butterfly network example.
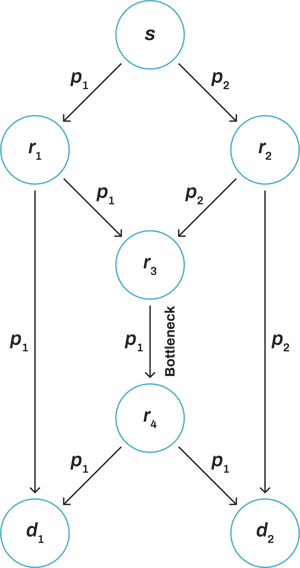
Suppose we have a network as illustrated above. We have a source node (e.g. a server) that is trying to send information (two packets) to two destination nodes (e.g. two mobile devices) - this is a typical multicast example.
In a store-and-forward network, you would send packets 1 and 2 over possible different routes and expect the network to handle the delivery of both packets to each of the receiving nodes. We can see that packet 1 could reach the destination node 1 via route s → r1 → d1. Similarly, packet 2 could reach destination node 2 via route s → r2 → d2. However, for the destination node 1 to get packet 2, we would need to rely on node r3 to send it to the destination node. Likewise, to deliver packet 1 to destination node 2, we would rely on r3 to send it to the destination node. This makes node r3 a bottleneck.
In a coded network, the flow of information would be very similar. However, the data flowing through the network would be substantially different. What network coding proposes is that nodes in a network can mix packets together (e.g. creating a packet that contains the XoR of multiple packets) and send these packets to the next node. This next node could again mix the packets it receives and send them to the next node. The process repeats itself until packets have reached their destination.
What changed here? Well, some very relevant things. First, nodes in the network do not store-and-forward anymore but rather operate over the packets they receive, generating coded packets (the mixed packets). Second, the destination nodes do not receive the data packets as they were originally generated (they now receive coded packets!), so destination nodes must be able to “decode” these packets. How would they do that, you may ask? Let’s go for an example.
In algebraic formulations of network codes (e.g. linear network codes), coded packets are generated as linear combinations of packets (coded packets are of the form p =ɑ1 p1 + ɑ2 p2 + ... + ɑn pn , where the ɑ‘s are called coding coefficients, p’s are data packets and n is the total number of packets we’re mixing). Our goal is to recover packets p1, p2, ..., pn . So, what we need to do is to get enough packets, such that we can solve a system of linear equations. If you remember from your algebra classes, this amounts to receiving n linearly independent combinations of packets (spoiler alert: this means that the way you choose your coefficients is really important to achieve high efficiency).
So, let’s get back to our butterfly network. How would the information flow through the network? Well, exactly in the same way. But now, we allow the bottleneck node r3 to generate coded packets.
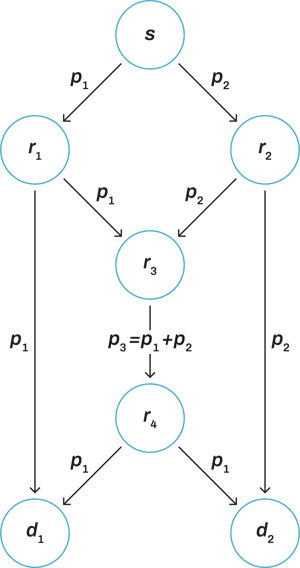
So instead of using two-time slots to send packets 1 and 2, node r3 can now combine these two packets together and send this linear combination to the next node. The node r4 sends this coded packet to destination nodes d1 and d2.
What happens at node d1? Well, it has received two packets: packet 1 via the route s → r1 → d1 and packet 3 (which contains packets 1 and 2 combined) via the route r3 → r4 → d1. Since d1 received two linearly independent packets, it can now decode packets 1 and 2 by solving the following system of equations:
So we save a time slot by allowing intermediate nodes to code these packets.
Hopefully, at this point, you’re convinced that network coding can effectively increase network throughput.
Yeah, I don’t actually think that multicast is that relevant…
You may (understandably) be worried that this would only happen in multicast scenarios. No need to worry, in unicast scenarios network coding can also increase network throughput.
Consider the following scenario: source node s1 wants to send packet 1 to destination node d2 and source node s2 wants to send packet 1 to destination node d1. There is no direct route s1 → d2 nor s2 → d1. In a store-and-forward network, r3 would need to make two transmissions: packets 1 and 2 would be sent in two different time slots. However, if we allow r3 to encode packets, we could benefit from the direct link between s1 → d1 and s2 → d2 to send information that would allow r3 to send a single packet. If s1 sends packet 1 to d1 and s2 sends packet 2 to d2, then r3 may only send the combination of these packets onwards, as both destination nodes would be able to recover their packet from the coded packet and the other packet received from a source node.
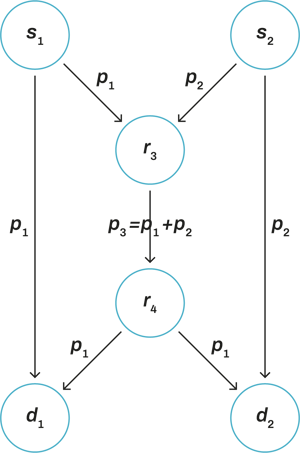
So you can see here that the core word is actually networks.
That’s beautiful, but it seems that you’re using a simple error correction code over a network
Well, there’s a reason you feel this way. What network coding does is very similar to an error-correcting code. However, the properties of the network code are fairly different from your traditional error-correcting code.
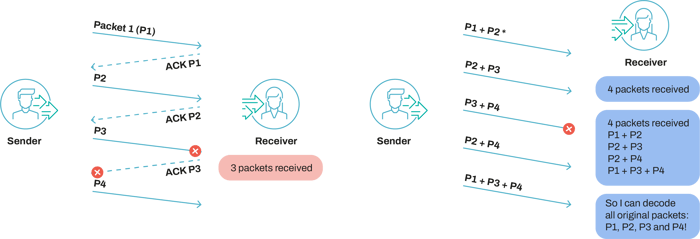
Keep in mind that error-correcting codes are designed for point-to-point communications (check this video if the above does not ring a bell). They do not care at all about the network. Data is encoded at the source, replayed at intermediate nodes, and decoded at the destination. Parity bits are added to the original data stream to allow for recovering any bit flips or erasures (see the illustration below).

In network coding however, intermediate nodes operate over the packets, creating new coded packets from the packets they received. And since they can also receive coded packets, this means the re-encoding must be possible.
Consequently, the most significant difference is that network codes allow for re-encoding at intermediate nodes without the need to decode the received packets, which is not necessarily true for error-correcting codes. These constraints make code design rather distinct.
Don’t get me wrong, error-correcting codes are the ones that allow you to have a reliable gigabit connection (LDPC codes are used for instance in the WiFi IEEE 802.11ac standard). They simply are not tailored to solve network problems.
And this leads me to the second relevant point. When you design an error-correcting code, you target some packet loss rate that the code should be able to overcome. This is fine when you think about point to point (everything in the middle is a link with some packet loss probability). In complex networks (such as the Internet) this can be an issue since your links have very different packet loss characteristics. Your wireless hop can be very lossy, one of the links in your route can be suffering from bufferbloat and dropping a few packets, etc, … This makes parametrization of error-correcting codes hard to generalize. You can have low overhead and small error-correcting capabilities or you have higher overhead, recover everything, but suffer the efficiency penalty of sending more data than needed.
When thinking about the multiple links in a network, the underlying concept of error-correcting codes does just not fit. Your code can be very efficient over one link but very inefficient over the other (not even thinking here about the variability of a single wireless link when subject to multiple users).
On the other hand, the concept proposed by network coding abstracts from all of this. You just simply send packets and the receiver needs to collect enough packets on its end to recover the original data. So you don’t necessarily need to parametrize for a specific link error rate - although you do have to design your code to be efficient in terms of generating linearly independent combinations, i.e. you have to worry about making every transmission useful to the client, but that would take another blogpost.
So, bottom line, network codes serve a different purpose than error- correcting codes and should be designed based on different criteria. But one does not replace the other!
So, what does network coding bring to the table?
We’ve already talked about how network coding can increase network throughput. Are there any more benefits? I don’t know about you but I’ve always liked a free lunch! (PS: I’ll keep the next sections more high-level since, with the basics layed down, the topics we’ll discuss should be more clear).
Well, let us list some of the other benefits of network coding:
- Latency: network coding enables low latency communication by the simple fact that it does not need to rely on ARQ systems. Store-and-forward systems generally rely on ARQ, and therefore the sender needs to wait for feedback to be able to send new data (it needs to know if and what packets were lost). Coding based solutions do not have this constraint. They can recover from packet loss even without knowing which particular packet was lost - “any” coded transmission can be used to recover the lost packet. So, we can build protocols that are not necessarily blocked by acknowledgments to send new data.
- Scalability: network coding enables a more efficient usage of network resources (bandwidth), therefore allowing the network to scale better. A particular case of this are multicast/broadcast networks, where coded packets can be used by multiple users to recover from different losses, therefore making an effective use of the available bandwidth, which means more users can be using the network
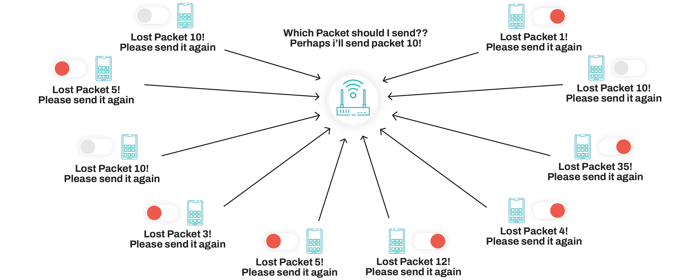
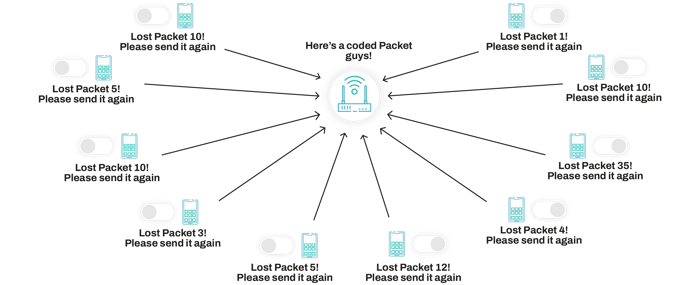
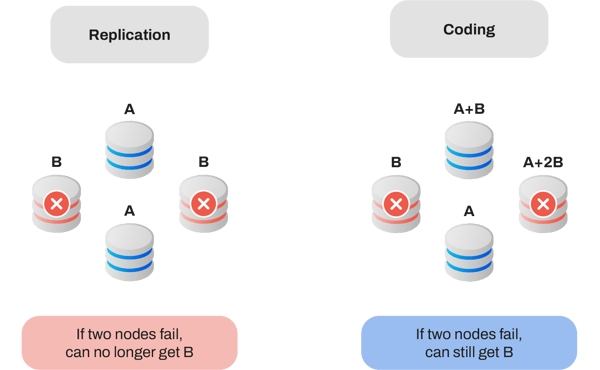
- Network resilience: due to its design, network coding also enables a high degree of network resilience. Think about a network where a node goes down. All the packets flowing through that route will be lost, therefore forcing the sender to resend them. With network coding, all these packets will be recovered from coded paths sent over other routes, overcoming any issues with node failure. The same is true for storage systems. If a database uses simple replication to ensure redundancy, you may create a great overhead and not even ensure basic redundancy, whereas if you use a coded data storage system, you can build inherent redundancy in your storage system, being capable of defining a much more interesting trade-off between reliability and overhead.
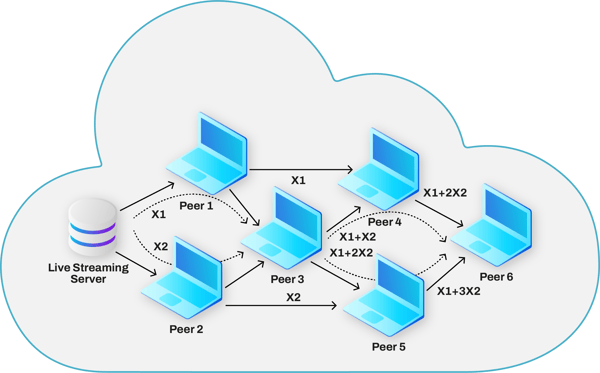
- Distributed storage and P2P systems: network coding also enables an intuitive and easy design for distributed storage and p2p systems. With network coding you do not need to fetch data from a particular server or user, you simply need to collect enough data from wherever it is available. Since all data chunks are encoded, they all possess relevant information from a decoding standpoint, and therefore we can recover the original data from any coded data we may find.
Why haven’t I seen any network coding based protocols in the wild?
This is a fair question. My intuition is the following: in practice, network coding may be implemented at any layer of the OSI model above the network layer. However, the origins of network coding are precisely at the network layer. This means that routers and switches must implement some form of network coding (i.e. they should be able to operate over packets and mix them together). Aside from these developments, you must also deploy all these devices across the globe. You can see how replacing the whole internet could be a little bit unfeasible.
You're now thinking that you’ve been reading all of this for nothing… Let me hold you back on those thoughts. While it may take “some time” to see network coding widespread across the globe, the concepts of network coding can be developed at higher layers in particular at the application layer. You’ll see it in a minute.
Building a new internet (with network coding)
Right! So far we’ve mostly discussed applications of network coding (multicast/broadcast/p2p) which represent a somewhat limited use case, but network coding can have a global impact. How, you may ask? It’s simple: we can use the network coding to develop new transport layer protocols, one of the core pieces of communication networks and used in every application that needs to access the Internet (we’ve written about this here, here or here in other scopes).
The heart of the network - the transport layer
We’ve unveiled a little bit of how network coding can be used to perform congestion control and flow control in the previous sections. Let’s expand a little bit on that.
HTTP rings a bell to you, right? It is an application protocol for transmitting hypermedia documents and resources. Basically, the foundation of the web as we know it. Under the hood, HTTP uses TCP (transmission control protocol) to reliably exchange data between two endpoints. (side note: HTTP/3 will be using UDP as a transport protocol). However, the performance of TCP is severely impaired by the presence of packet loss and latency. The reason is two-fold:
- TCP (in general) interprets packets loss as congestion and reduces its transmission rate
- TCP is based on ARQ and therefore highly dependent on feedback packets to operate
Now, the first premise is not really valid in today’s world, specifically when speaking about WiFi/mobile. Packets get lost for many reasons! Interference, signal propagation issues, faulty hardware and so on. So, if you’re experiencing random packet losses why should you reduce your transmission rate? These losses do not necessarily mean that you are congesting the network…
The second point, we’ve discussed a little bit. Do we really need to wait for acknowledgments to be able to operate a reliable transport protocol? If you are sending untouched data yes, you need your packet sequencing and everything in between. But if you are using coding, not really… Any packet can be used to recover useful data.
So instead of reasoning about losses as signals of congestion, we may look at how much information is passing through the channel (goodput). This way, you’ll get a much better idea if you are actually congesting the network. And, in a network coding mindset, goodput is simply the amount of information your receiver is able to decode.
What network coding offers to the transport layer is the following:
- Intrinsic loss recovery (any packet can be used to recover data in a stream)
- The possibility of designing congestion control mechanisms based on decoded information (packet loss can be easily taken out of the equation and we can focus on more relevant metrics such as goodput, latency, whatever…)
- New ways of acknowledging data (we don’t need to wait for feedbacks anymore, data will get there eventually)
- New flow control mechanisms (we can create coding schemes for optimizing different metrics such as immediate decodability, pure throughput, packet prioritization, ….)
So, in effect, network coding allows you to design a better transport layer protocol and consequently a better Internet for all!
(At the end you’ll find some links with performance numbers comparing ARQ and network coding based protocols, feel free to check them out!)
What would the world look like if network coding was everywhere?
One image is worth a thousand words:
- Users over wifi/cellular/mesh would get an awesome performance everywhere!
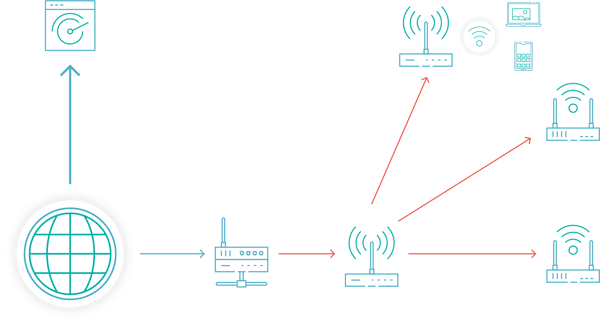
- Users using a public/dense WiFi network would have a great experience!

- Distributed storage with automatic fault tolerance
Finally....
You can breathe now… Let me just give you some takeaways!
What we’ve talked about:
- How you can use network coding to improve network throughput
- How you can use network coding to scale the number of users in wireless network
- How you can use network coding to improve transport layer protocols
What we did not talk about:
- How to design your network codes (heuristics, optimizations, ...)
- How to implement (packet structures, encoding/decoding algorithms, ...) your network codes
You already have a lot of info to process, but let me leave you some nice links if you are interested in more network coding stuff...
Network coding applications:
Benchmarks and numbers:
- How fast is QUIC protocol and what makes Bolina faster - PT. I
- How fast is QUIC protocol and what makes Bolina faster - PT. II
- Benchmark - RLNC vs RaptorQ
Myths:





