TL;DR: How do we use HashiCorp’s Consul to deal with service discovery in our CDN service and why do we do it instead of using Kubernetes native service discovery.
Kubernetes service discovery
If you have a Kubernetes cluster you certainly had to deal with the numerous copies that your microservices can have and how they communicate with other microservices, in your cluster, and to the outside. Being able to scale your services is very good to keep up with demand but can be really tricky to manage since new pods are created and your services are accessible in multiple network endpoints (i.e. some IP and port).
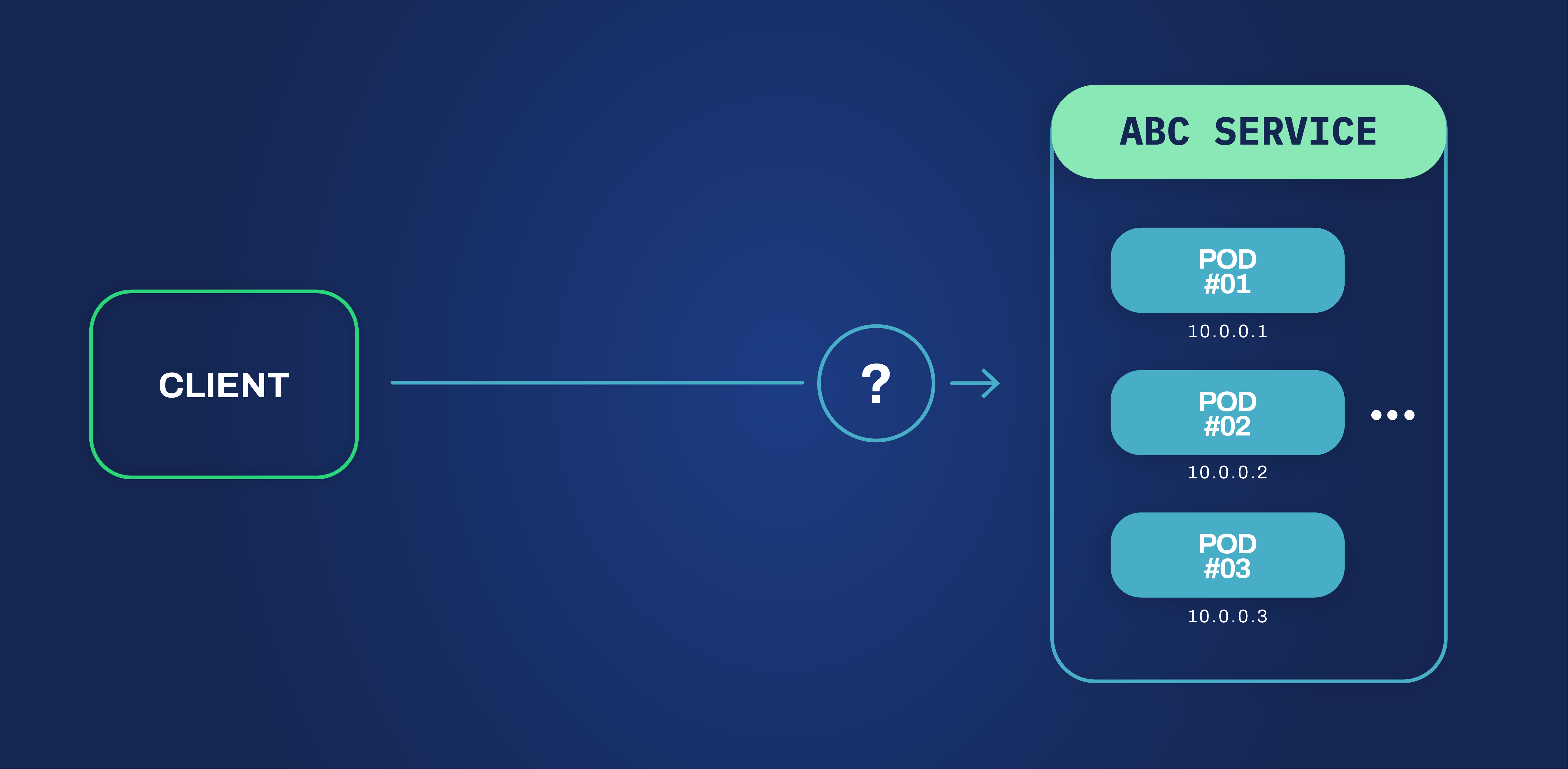
This is where service discovery comes in handy. Service discovery is the process of locating a service, once it’s determined that said service is integral to completing tasks. The two main types of service discovery are client-side and server-side service discovery. Client applications can use server-side service discovery approaches to support via a router or load balancer. Client-side service discovery lets client applications locate services by searching or asking for a service registry containing service instances and endpoints.
Kubernetes native service discovery
Since we already know what service discovery is and what it does, let’s dive into how it works on a Kubernetes cluster. First, we should talk a little about pods. Pods are the smallest deployable units of computing that you can create and manage in Kubernetes. It is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers. In what concerns networking the documentation states “...Pods can be treated much like VMs or physical hosts from the perspectives of port allocation, naming, service discovery, load balancing, application configuration, and migration.”
So if Pods can be treated as single hosts of a service we would expect some analogy for the grouping of those instances, right? And indeed Kubernetes gives us that concept that is called, guess what, Service. As per documentation, “In Kubernetes, a Service is an abstraction which defines a logical set of Pods and a policy by which to access them (sometimes this pattern is called a micro-service)”. Since the Kubernetes service contains all those pod endpoints if for some reason some pods crash the service will not have a stable headcount of pods, being as ephemeral as the pods are. This is where Kubernetes API comes in. It is responsible for keeping an up-to-date registry of the endpoints available for the service. When a client needs that specific service it can use the Kubernetes API to retrieve an endpoint and establish a connection directly with the pod.
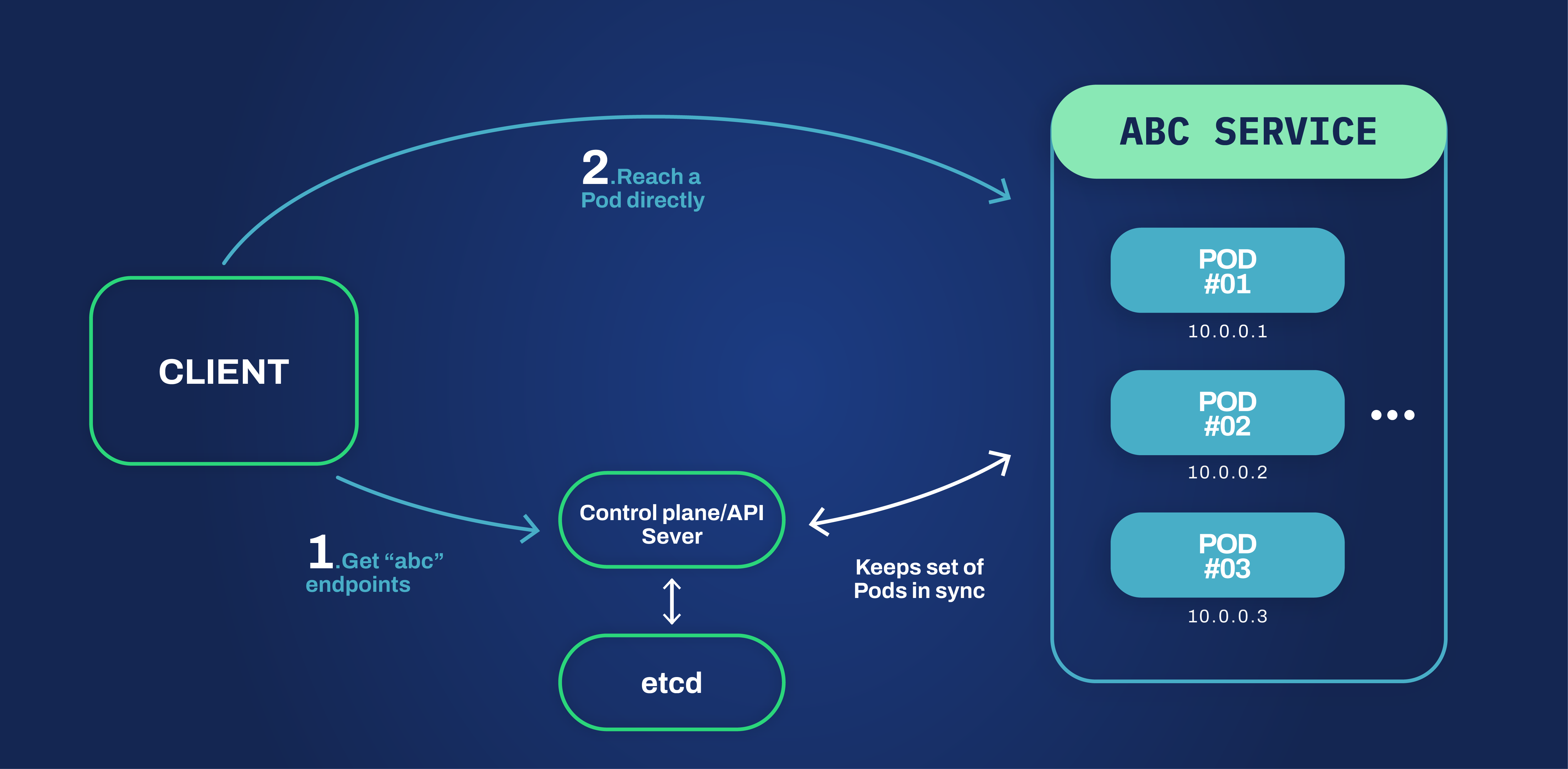
This works fine if our clients can use the Kubernetes API. However, for those clients that do not support it, there is another way of getting the same type of connection. We can take advantage of the built-in DNS service provided by Kubernetes and our services would be reachable to others by a domain name, typically <service-name>.<namespace-name>. This method will resolve the DNS domain to the clusterIP of the service. Then, this clusterIP is transparently replaced by the client node’s network stack with one of the services’ pods to allow the client to reach it. Unfortunately, there is a big downside to this last approach in our use case that we will discuss in a few moments.
Why don't we use the Kubernetes’ native service discovery, but go for Consul?
So, why do we think we are better off using Consul instead of the Kubernetes service discovery? Let’s start by explaining the needs of our infrastructure, then compare the differences between Consul, Kubernetes, and other service discovery mechanisms in a more generic way, and finally, dive into our specific use case.
For our infrastructure to work properly we need to be aware of the availability of service pods. We need to know their IP addresses, in order to reach them inside of the Kubernetes cluster and also their health status. To assess this health status we can use different metrics and a key/value store comes in handy to store that information for each pod. If a specific pod gets overloaded we should not send any more packets to that specific pod and choose another one to do the processing. Here enters another critical component, the Envoy Proxy. It is responsible for receiving all the packets from the outside and redirecting them to a Bolina Server pod. Envoy needs to know to which Bolina Servers it can send packets, and the service discovery mechanism starts working on this point.
Taking this into account let's make a quick table to compare the main features of all of the available tools to help us have a better overview of the pros and cons of each tool.
| Service Discovery | Key/Value store | Health checks | Multi-cluster | |
| Kubernetes + etcd | Built-in | Yes | Yes | No |
| Consul | Built-in | Yes | Yes | Yes |
| Zookeeper | Custom-built | Yes | No | No |
| Eureka | Built-in | No | Yes | No |
| SkyDNS | Built-in | Yes if etcd is used | Yes | No |
We can immediately rule out Zookeeper since we would need to implement the service discovery mechanism as it is not provided a built-in service discovery mechanism. Eureka can also be discarded as a key/value store is not implemented. SkyDNS seems promising but it relies on naive heartbeating and TTLs, an approach that has known scalability issues.
Two options remain, Kubernetes + etcd and Consul. At a first glance, everything lines up so that we should be able to solve our service discovery problem with native service discovery from Kubernetes + etcd since we do not need the multi-cluster feature that Consul provides. However, there is more to add to the picture than those generic features. If we opted for Kubernetes we would be stuck to always using Kubernetes, on the other hand with Consul we could deploy the same services on a different platform. Another point in favor of Consul is that some of our software pieces are not Kubernetes API capable, which means that to use Kubernetes’ native service discovery we would need to implement an integration.
As we saw earlier, instead of implementing an integration, we could take advantage of the DNS service provided by Kubernetes for those clients that do not have access to the Kubernetes API. Unfortunately, that is not a feasible solution for our use case, but why? On our servers, we have implemented a mechanism to keep persistent connections, which requires that the communication from a client is done to the same server. Therefore, if a client already established a connection with a server before it must connect with the same server again in order to keep that persistent connection. That would not be possible with that type of mechanism, since the DNS resolution uses round-robin scheduling to determine which IP address to answer. If a different IP address is given the connection will be broken. This happens because we are using UDP, with TCP the connection is kept open but with UDP we don’t have a connection open, so we have to make sure the packets are redirected to the same server.
How did we solve the problem?
To solve the traffic redirection problem that we had on our hands we chose Consul to be our savior. Why? Because Consul has some great tools that can help us solve that in an easier way than the others. The availability of the Consul Agent allows us to easily integrate our own software pieces with Consul through REST APIs. Even though Kubernetes also has REST APIs available there is no client for C++ implemented, which means that we would need to create one ourselves. This easy integration with the Consul Agent enables us to have the up-to-date status of our servers in what concerns the load in Consul. Here is where the key/value store from Consul gets to work in our favor. It is capable to store the load for each Bolina Server pod as well as other metrics. For a better picture of how this is helpful, let's get into more detail about our infrastructure and what is the flow when we receive a packet. We can remove from the picture the software we don’t need right now and focus more on the main intervenients of this discussion. Our infrastructure relies on Envoy Proxy, Consul (as-a-cluster), and two personalized software pieces that we call Bolina Server and Watcher to receive and manage the flow of packets as well as the scalability of the infrastructure.
Let’s start with the Bolina Server and describe how it interacts with Consul. The Bolina Server is the one that interacts less with Consul, not because it’s hard to do it but because we don’t need more. It uses the Consul Agent to send data to Consul. Since the Bolina Server is a custom software piece made by us we had to implement a way of sending the data to the Consul Agent. The agent's REST APIs allow us to send data in a fairly easy way from our server and implementing that is also no hard task. The Bolina Server is then capable of periodically sending an update of its health status to the agent, which updates the status in the Consul cluster. On the Consul UI, we can have an overview of the Bolina Servers that are currently up and also see the health condition of each one.
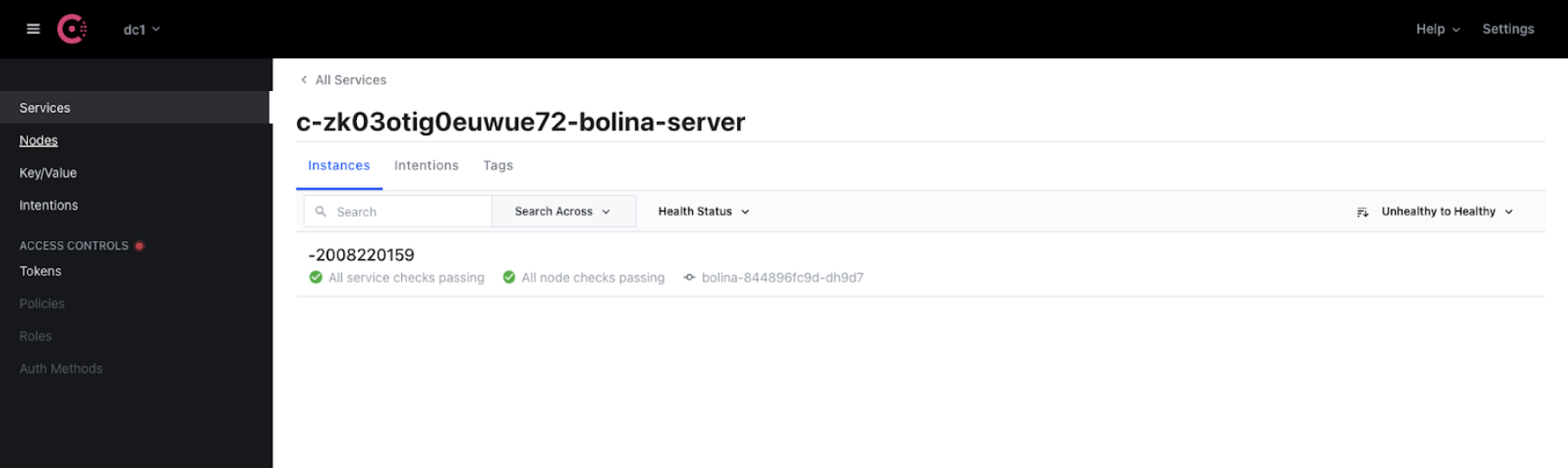
If we had a Bolina Server in a warning state it would show like the Bolina Server with the ID -2008220159 on the UI.
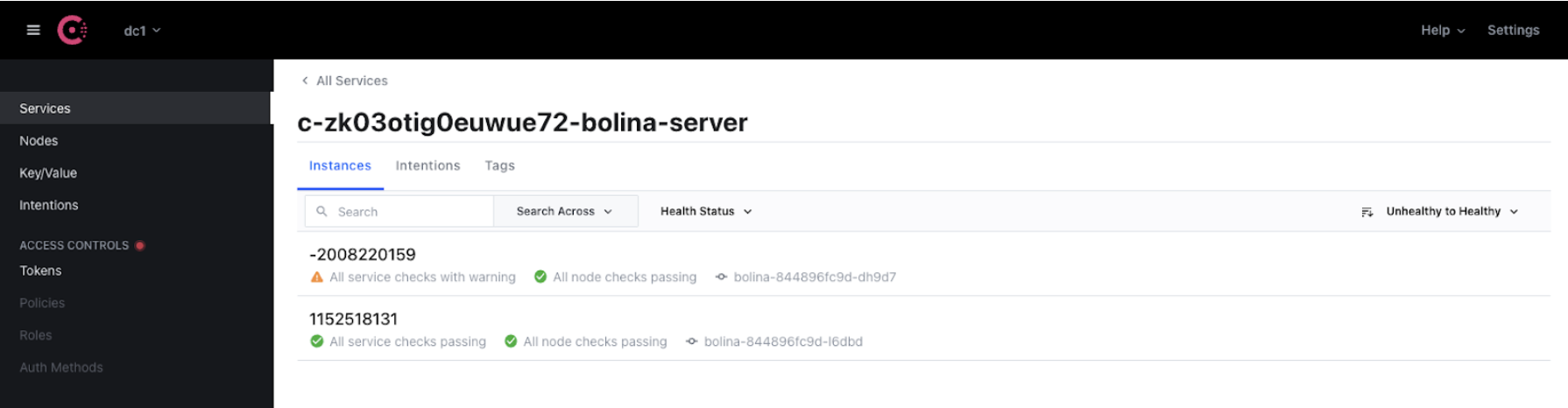
This is very important because having the health status up-to-date enables us, as we discussed previously, helps us to better distribute the load between the Bolina Servers and keep our service available at all times.
Jumping now to the Envoy Proxy, it is responsible to handle packets and also works as a load balancer to our infrastructure. Envoy Proxy is capable of redirecting traffic based on different metrics and also be a firewall. Taking advantage of its integration with Consul, via a Consul Agent, Envoy Proxy is able to know how many Bolina Servers are up and running and registered on Consul as well as their IP addresses. We then continuously monitor changes in the health status of each Bolina Server through Consul which allows us to automatically update the configuration of Envoy and base our packet routing on that. That is done using Endpoint Discovery Service (EDS) which provides a way for an Envoy deployment to circumvent the limitations of DNS (maximum records in a response, etc.) as well as consume more information used in load balancing and routing without the need for any restart of the service. For example, if a Bolina Server is in critical condition Envoy is aware of that and if a packet by a new client is received it will not redirect that packet to that Bolina Server. Instead, it will redirect the packet to a healthy Bolina Server. However, if the client has been seen before Envoy will know that and redirect the packet to the same Bolina Server even if it is in critical condition. This is the behavior we want in order to keep the persistent connection working. Envoy also allows us to have a first barrier point since it rejects malformed packets avoiding those packets flowing into our internal network thus saving resources.
Last but not least, the Watcher. It is responsible for the scalability of our services, specifically the Bolina Server. The Watcher is Kubernetes API capable and due to the Consul Agent is also able to detect changes in the Bolina Server health condition. We can then, based on certain requirements, decide if we should scale the number of bolina pods up or down through the Kubernetes API. This mechanism is very important because it assures that our infrastructure is always available and that Codavel’s CDN is never interrupted.
Wrapping things up
We discussed a lot of things, so let's put it all together. Kubernetes’ native service discovery allows us to access multiple pods using the same endpoint. This is good because the scalability of our services turns out to be a simple problem to solve, which makes those services more robust and keeps that scalability transparent to the end-user, being that another pod or an outside client. However, for Codavel’s CDN the native provided features weren’t enough so that we could make it work without a lot of effort. For that, we had to build a different structure using HashiCorp’s Consul.
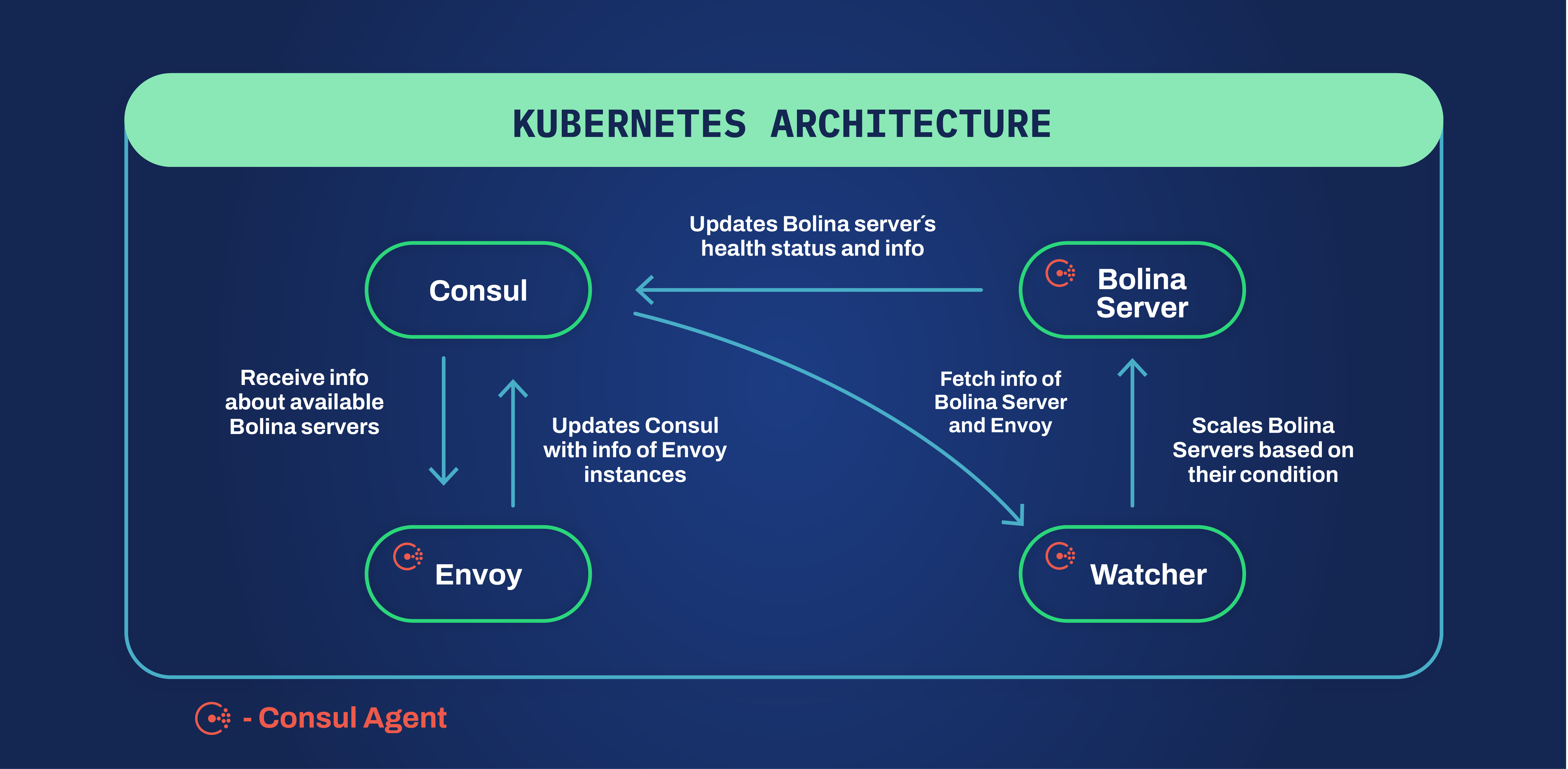
This new setup provided everything we needed to make our service work, and be robust and scalable. The availability of the Consul Agent made the integration with Consul much simpler and allowed automatic detection of Bolina Server’s health condition changes and also how many Bolina Server pods were running and their details. To sum everything up, here’s a list of the main reasons why we use Consul:
- Easier integration with infrastructure services/software
- Allow us to be platform-independent
- Automatic detection of the health status of each Bolina Server pod by Envoy Proxy
- Easier packet routing based on automatic detection of available services
And that’s it. This is why and how we use Consul on our infrastructure.

.png)