.png)
TL;DR: How do we use Rancher’s RKE and Hashicorp’s Terraform to deploy a consistent CDN service on multiple locations and cloud providers, and why does that makes us faster and more efficient.
How we deploy a Mobile CDN
Building a product from scratch is always a challenge. If that product is being built by a startup that needs to quickly prove its worth, the challenge grows. If that product has major infrastructure needs and aims to have a worldwide presence, you’re in for one tremendous ride.
And our ride has been… Let's call it interesting. But starting from the beginning: our product is a Mobile CDN, with points of presence (PoPs) spread all around the globe, that communicate with our mobile SDK through our mobile-first protocol, Bolina. Our goal is to ensure that every user gets an engaging and frictionless experience, no matter where the user is or the device or network quality. And in the next few (maybe more) lines I’m going to try to explain how we built it and how tools like Rancher’s RKE or Hashicorp’s Terraform, or Cloud Providers like AWS, Digital Ocean, Linode, and others help us move faster.
Codavel POPs
Efficiency, efficiency, efficiency
One of our company’s core values is to be efficient, and we try to apply that not only to our day-to-day work but also to every major decision. Efficiency basically means not wasting more resources than you actually need, but we tend to forget what “resources” are: it’s not only about the machines’ uptime or the CPU usage, but also about people and their time and focus. We truly believe that to be successful you need to focus and spend your energy on the things that you are really good at, which, in our case, is network performance. And since the beginning we knew that, although crucial, network performance is not only about what Congestion or Flow control your protocol uses, and that components like load balancing or content caching can also make a significant difference in a mobile app’s performance. Not to mention all the scaling challenges that delivering a service to millions of users spread around different locations would eventually bring.
We always knew the massive challenge ahead of us and the number of things we would need to tackle, and to quickly prove that we can truly make mobile apps faster, we had to avoid tackling a million other issues in the areas where we are not currently experts. As a result, we decided to focus on our core technology and leverage the work of others to build the other components, such as infrastructure.
So, while we developed our core protocol, Bolina, and all the other services built on top of it that compose our CDN, we decided to start looking for Cloud / Baremetal providers where we could deploy our services. At this point I’m guessing you are probably raising your eyebrow: “Wait! You said that you are efficient, but you built your own CDN?. Why not simply use an already established CDN and focus your resources on only developing the protocol?”. Well, there is an explanation for why we didn’t follow that path. And no, being crazy was not (directly) involved in that decision.
Our protocol uses encrypted UDP and TCP messages. And while most CDNs do an amazing job deploying, replicating, and protecting HTTP-based services that rely on standard TCP, integrating a custom communication protocol into a typical CDN would, if possible at all, require a lot of effort.
Going back to the infrastructure, and since we were looking for a worldwide presence, another challenge that popped up was the fact that different regions have different providers, with different pricing and possibly different types of machines, and the perfect cloud provider for India could eventually not be the best solution for a different PoP in Nigeria. We just had to be ready to deploy our services on whatever infrastructure was the most efficient for a specific location. While this, at first sight, may not seem like a huge challenge, trying to deliver a consistent experience across all Codavel’s enabled locations, independently of the infrastructure where the service is running, raised a few questions:
How can we ensure that everything was deployed equally, or at least that every functionality has the same behavior, independently of how it was deployed? And how to minimize the effort to replicate any changes that may be eventually needed? And as important, from the developer's point of view, how do we minimize the time required to test and validate any new development?
Fortunately, we found a few tools that answered our questions. Or prayers, to be more honest.
One Engine to rule them all
At this point, pretty much anyone that has scaling concerns and services based on containers and microservices knows the benefits of using Kubernetes. But before Kubernetes was mainstream (yes, I’m that old), deploying a service with such characteristics involved a lot of configuration and testing. As an example, our pre-Kubernetes CDN setup based on AWS required us to configure IAM roles and Security Groups, SNS topics, Auto scaling groups, and Launch Configurations, ECS, and Lambdas, with a lot of manual configurations, for each deployment and with a total deployment time of up to 24 hours(!): remember that talk about being efficient, right? And even though AWS is not exactly known for its lack of complexity, the worst part, and please note that I’m stating that taking 1 day to deploy the services was not the worst, was that if we wanted to deploy the exact same services on a different cloud provider, this meant changing to a totally different ecosystem and a lot of development time to port it to another platform/services and ensure that all services were running equally. Plus, since there were a lot of configurations to be done, there were also a lot of chances to make some mistakes somewhere along the process, and therefore we also needed to spend more time testing the product end-to-end.
So you could imagine how happy we were after we successfully migrated to Kubernetes and reduced our deployment time to a few minutes and a couple of scripts. That was it, right? Well, not quite. We still have to create and configure a Kubernetes Cluster every time we wish to deploy our services in a new location. And even if it's true that most cloud providers have their own managed Kubernetes service, and their core functionality is the same, deploying on EKS, AKS, GKE, DOKS or LKE is not entirely equal, and each one has its pros and cons.
There is also the issue with keeping the behavior of the cluster autoscaler consistent, but that alone is subject to another blog post.
We started to look for solutions to this problem and there was one project that kept being suggested: Rancher’s RKE. Long story short: we are now part of the team of people who recommend it.
From their documentation, “Rancher Kubernetes Engine (RKE) is a CNCF-certified Kubernetes distribution that runs entirely within Docker containers”. They are vendor independent, which means that as long as you have docker installed on the machines, you’re good to go. Independently on if the machines are hosted on a cloud provider, bare metal provider, or even in your home setup, Rancher’s RKE deals with all the setup, installation, and configuration required to run a production-ready Kubernetes cluster, and with just a few clicks (or using the CLI, we won’t judge you). Exactly what we were looking for: simple and consistent. Neat!
But is it really that easy?
Now let me show you exactly how easy it is to actually deploy a cluster using Rancher’s UI.
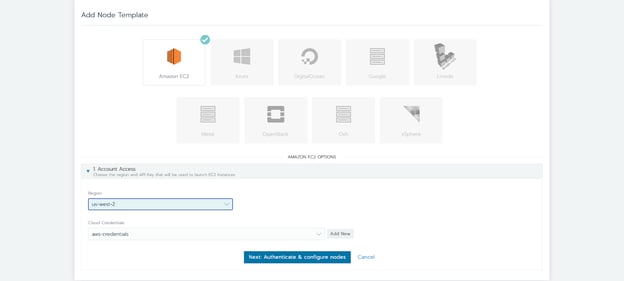
Our typical setup consists of two groups of Kubernetes nodes, where each node of that group has the same configuration (node pools): one for the control plane(s), where we run etcd and the Kubernetes API, and other for the workers where we actually run our services. Each node pool is responsible for ensuring that the desired number of instances is running and also makes it very easy to scale (if the infrastructure allows it) when needed. Rancher allows the creation of node templates, which, as the name implies, can pre-configure things like the type of machine that should be used, the region where the instances will be deployed, security rules, credentials, and other options.
Back to our guide, and taking AWS, again, as an example, we start by creating a node template with our API credentials and select the region, security group, and the type of machine that we want to deploy.
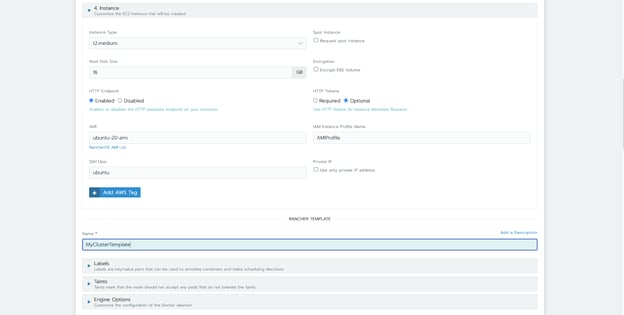
Time to move to the actual cluster deployment. Rancher presents a list of the supported cloud providers where you can install RKE (more can be added by importing or creating a specific node driver), but you can also install it on custom machines by selecting the option “Existing nodes”, which shows the docker commands that you need to run to start the service on each node.
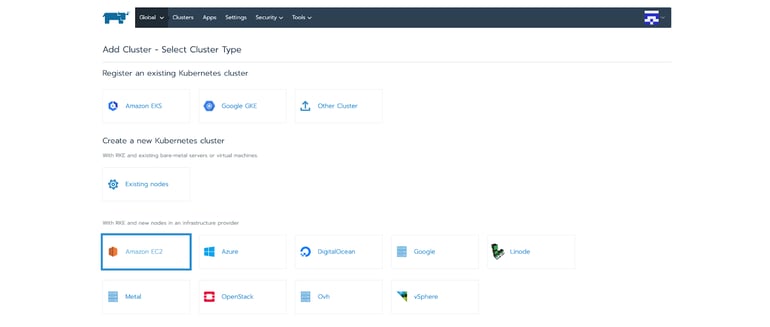
Following our example, after selecting to install RKE on AWS, we can name our cluster and select the node pools to be used, and its responsibility. Rancher also allows us to configure who has access to this cluster, the Kubernetes version, the CNI to be installed, and a lot of other advanced options, depending on the provider being used.
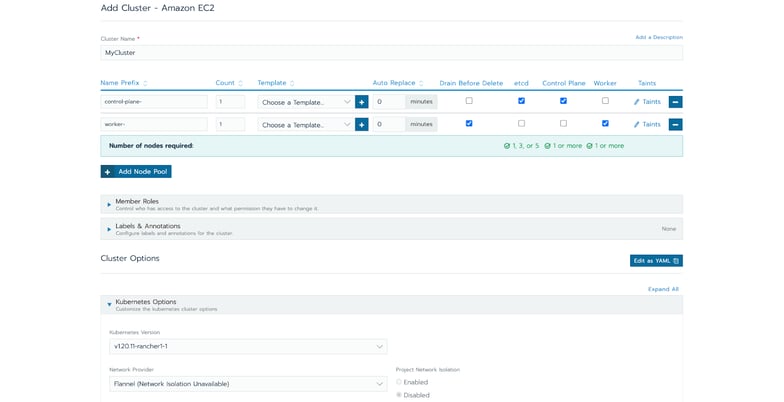
Click on Create and RKE will start provisioning the machines and installing the necessary components. After some minutes, the cluster is ready to be used and a kubeconfig to access the cluster can be directly downloaded from the Rancher’s UI. On top of that, you can also have access to a “Cluster Explorer” tool, which allows you to monitor and interact with the cluster and all the workload deployed, as well as some really cool dashboards that allow you to quickly have a glance at your Cluster’s status and check if everything is running as it is supposed to.
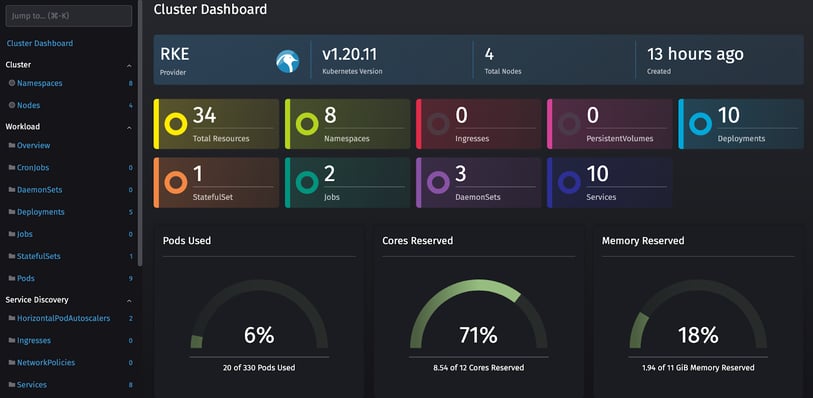
Is it enough? It never is!
We moved from a deployment time of around one day to some minutes. That was an important achievement and a boost in our productivity. But we were not satisfied. Rancher’s UI is pretty cool but there was still some manual setup required every time we created a new PoP, even if most of the configurations were the same. And you can be sure that even if we have only one configuration where we needed to select between left and right, someone would eventually select the wrong option at some point. And with a high probability that someone would be me.
Thankfully, we successfully integrated with another popular tool: Terraform.
Terraform is an infrastructure as a code tool. You define the infrastructure you want to deploy through code, in a declarative style, and Terraform is then responsible for figuring out how to move from the current state to the one you requested. The code submitted represents the state of your infrastructure, which makes it very easy to read and understand what you have deployed. Besides that, since it is code, it also enables the possibility to implement coding principles, to have source control, implement automated tests or even integrate it into a CI/CD pipeline. I’m not going to dive deep into the details of this tool (in case you want to read more, I strongly recommend their documentation, which is really awesome), but rather show how we use it to create our RKE clusters.
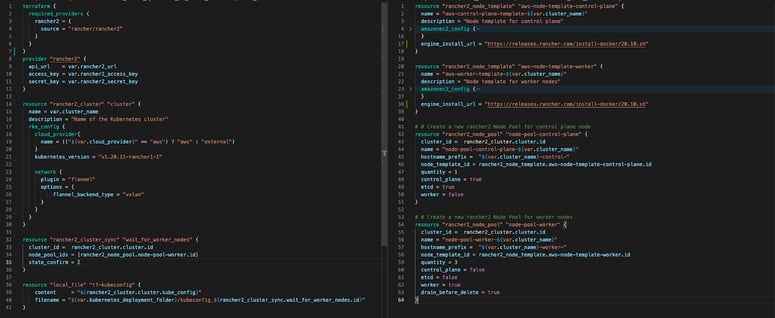
Terraform relies on plugins called "providers" to interact with other APIs. Luckily for us, RKE has its own provider, https://registry.terraform.io/providers/rancher/rancher2/latest/docs, that can simply be enabled by placing this at the top of your main Terraform script and then configuring the provider with the Rancher’s API access key and secret:
terraform {
required_providers {
rancher2 = {
source = "rancher/rancher2"
}
}
}
provider "rancher2" {
api_url = var.rancher2_url
access_key = var.rancher2_access_key
secret_key = var.rancher2_secret_key
}
Using this provider, we can easily create the same AWS node template as we did through the UI previously, by adding this resource to the terraform script (and a similar one for the Control plane):
resource "rancher2_node_template" "aws-node-template-worker" {
name = "aws-worker-template-${var.cluster_name}"
description = "Node template for worker nodes"
amazonec2_config {
access_key = var.access_token
secret_key = var.aws_secret_key
security_group = ["Security Group"]
iam_instance_profile = "IAMRole"
ami = var.aws_ami
region = var.cloud_region
subnet_id = var.aws_subnet
vpc_id = var.aws_vpc
zone = var.aws_availability_zone
instance_type = var.aws_instance_type
request_spot_instance = var.aws_spot_instance
spot_price = var.aws_spot_price
tags = "Name,[${var.environment_name}] Worker-${var.cluster_name}"
}
engine_install_url = "https://releases.rancher.com/install-docker/20.10.sh"
}
Then, to create an RKE cluster, we create two different node pools, one for each node template, and the cluster itself (in this example we selected Kubernetes version 1.20.11 and flannel as the CNI):
resource "rancher2_cluster" "cluster" {
name = var.cluster_name
description = "Name of the Kubernetes cluster"
rke_config {
cloud_provider{
name = (("${var.cloud_provider}" == "aws") ? "aws" : "external")
}
kubernetes_version = "v1.20.11-rancher1-1"
network {
plugin = "flannel"
options = {
flannel_backend_type = "vxlan"
}
}
}
}
# Create a new rancher2 Node Pool for control plane node
resource "rancher2_node_pool" "node-pool-control-plane" {
cluster_id = rancher2_cluster.cluster.id
name = "node-pool-control-plane-${var.cluster_name}"
hostname_prefix = "${var.cluster_name}-control-"
node_template_id = rancher2_node_template.aws-node-template-control-plane.id
quantity = 1
control_plane = true
etcd = true
worker = false
}
# Create a new rancher2 Node Pool for worker nodes
resource "rancher2_node_pool" "node-pool-worker" {
cluster_id = rancher2_cluster.cluster.id
name = "node-pool-worker-${var.cluster_name}"
hostname_prefix = "${var.cluster_name}-worker-"
node_template_id = rancher2_node_template.aws-node-template-worker.id
quantity = 1
control_plane = false
etcd = false
worker = true
drain_before_delete = true
}
And that’s it! In case we want to deploy in another Cloud provider, like Digital Ocean, for example, we just need to replace our node template with something like this:
resource "rancher2_node_template" "do-node-template" {
name = "do-node-template-${var.cluster_name}"
description = "Node template for worker nodes"
digitalocean_config {
access_token = var.access_token
region = var.cloud_region
private_networking = true
size = var.do_size
image = "ubuntu-18-04-x64"
}
engine_install_url = "https://releases.rancher.com/install-docker/20.10.sh"
}
Another interesting resource of this provider is the rancher2_cluster_sync. Our goal was to hook terraform with our scripts that installed our services on the Kubernetes cluster through kubectl. Ideally, those scripts should only run after the cluster is properly deployed and ready to accept commands, and only if the cluster was created successfully. The cluster_sync doesn't create anything on the Rancher side but rather acts as a dummy resource used to wait for a specific state of another resource. In our scenario, we create this resource to wait for the Worker’s node pool to be ready, which means that the cluster is ready to actually start working
resource "rancher2_cluster_sync" "wait_for_worker_nodes" {
cluster_id = rancher2_cluster.cluster.id
node_pool_ids = [rancher2_node_pool.node-pool-worker.id]
state_confirm = 2
}
Finally, as a bonus, we also use terraform to extract the kubeconfig file generated by Rancher and store it in a local file. This is used afterwards by our kubectl-based deployment scripts, but also useful when we are too lazy to login into Rancher’s UI to access the cluster:
resource "local_file" "tf-kubeconfig" {
content = "${rancher2_cluster.cluster.kube_config}"
filename = "${var.folder}/kubeconfig_${rancher2_cluster_sync.wait_for_worker_nodes.id}"
}
Then we just need to run “terraform apply”, go grab a coffee, and check that our CDN is ready to use!
Can we get back to the performance now?
Using Rancher’s RKE and terraform helps us optimize and streamline the deployment of our CDN service, which is based on Kubernetes. It also helped us to significantly reduce the probability of a misconfiguration due to human error, and also the need to have specific knowledge on how to deploy such services on different cloud providers. Another side effect of this, but equally important, is the impact it had on the development process. Any developer on our team is now able to easily and quickly create a fully working environment similar to the one we use in production, and we can avoid having long-running machines or mocking some services just to not go through all the necessary steps to deploying them.
But on top of all that, it also was used as the first step to our fully automatic deployment, where this all can be triggered through our CI/CD pipelines or through a serverless function. We just need to configure where we want to deploy our services, eventually configure some cloud credentials or other minor configurations, leave the remaining boring part of the process to Terraform and RKE, and go back to discuss how to improve performance, which is what we are really passionate about.
If you want to explore what can a Mobile CDN do for your app, we would be happy to help!


.png)




