
TLDR: QUIC and Bolina are new UDP-based transport protocols that aim to deliver a low-latency, reliable, secure and fast connection between end-hosts. This post is part II of a performance comparison of these two protocols, to better understand why is Bolina faster. Here’s part I if you haven’t read it yet.
As you may have seen in our previous post, QUIC showed some performance limitations when dealing with latency and packet loss. QUIC achieved good improvements when transmitting a relatively small amount of data, but showed the same impairments as TCP when transferring bulk data. On the other hand, Bolina showed more robustness to both these network variables.
That could be “surprising”, but it is actually not. Mostly because QUIC inherits its “modus operandis” from TCP, focusing on implementing optimizations for the connection startup phase. Let’s quickly recap the downsides of QUIC which I highlighted in my previous post:
- QUIC uses ARQ to recover from losses, which means it slightly lags when advancing its transmission window (this is specially relevant in a network where packet losses and delayed/out-of-order packets are common - e.g. wireless networks);
- QUIC does not revisit the congestion control, following the paradigm of existing TCP standards (most of which deal poorly with latency and losses).
In this blogpost, I will explain how Bolina shifts from the networking paradigms imposed by TCP and QUIC, and how these changes contribute to a superior performance.
An overview of congestion control
As a starting point, let’s check how TCP does congestion control (of course this depends on which TCP version is used, but we’ll try to give a general idea of the underlying mechanisms, namely the NewReno congestion control).
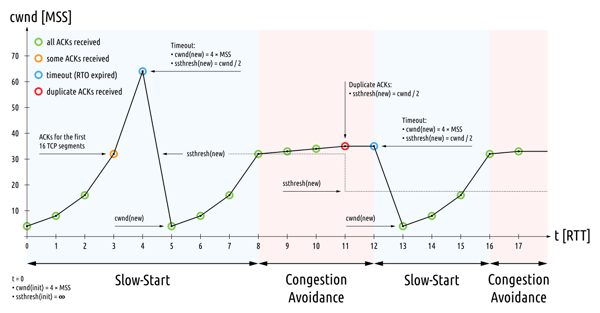
TCP has an initial window of some segments of data that it can send on bootstrap. In the first phase (slow-start), for each segment acknowledged TCP can send another segment of data (exponential increase). This process goes on until either:
- a loss is detected, in which case TCP goes to a congestion avoidance phase;
- a slow start threshold has been reached, in which case TCP goes to a congestion avoidance phase;
- a flow control limit (rwnd) has been reached, in which case TCP does not increase the amount of data it can send;
- a timeout occurs, in which case the window will default back to its initial value and slow start threshold becomes half the congestion window.
During the congestion avoidance phase, the amount of data to be sent by TCP can increase linearly (1/cwnd). Additionally, detected losses will cut the slow start threshold to half the congestion window.
So, we can say that when TCP detects a lost packet, it takes “extreme measures”. This is done because a packet loss is interpreted as a sign of network congestion and so we should slow down. In the day and age of wireless communication systems, this assumption is, to say the least, misleading. There are many other reasons for packet loss (interference, propagation related losses, device limitations...).
Fixing issues instead of solving problems
TCP evolved to schemes that use selective acknowledgements (the receiver explicitly lists the packets it has received) and delayed acknowledgements (the receiver delays the transmission of the acknowledgment to combine several acknowledgments together), that enabled different types of loss recovery strategies, from Fast Retransmit, to Early Retransmit, FACK and SACK. The main idea was to provide a way to pinpoint which packets were lost (by means of selective acknowledgments) and retransmit them as early as possible.
QUIC introduced improvements over this strategy:
- it increases the SACK/NACK range allowing you to provide more information to the sender about lost packets
- it introduced monotonically increasing packet numbers to disambiguate delayed packet from retransmission (more accurate RTT measurements) and
- it changed the way packet loss is detected: instead of using the traditional 3 duplicate ACK strategy used by TCP, it uses packet threshold and time threshold variables that define the conditions for which a packet is presumed to be lost (if a packet is behind the last acknowledged packet more than the packet threshold or it has not been acknowledged with a time frame that depends on the time threshold, the latest RTT, a smoothed RTT measurement and a minimum time threshold value).
These solutions do minimize the problem at hand: they reduce the number of spurious retransmissions. However, the inherent deficiencies of ARQ are still there! And without a proper congestion control, the potential of these improvements is much more limited (every loss is treated as a congestion!).
Coding-based congestion control
Bolina is based on a technique called network coding. In essence, network coding is a coding technique that allows packets to be “mixed” within a network. More precisely, it allows for linear combinations of packets to be transmitted from sender to receiver. Provided that the receiver obtains the right amount of combined packets, it is able to decode them. The following picture illustrates the basic workings of network coding.
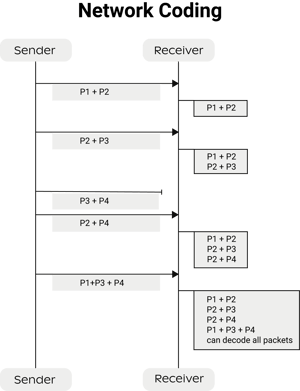
Note that the sum operation depicted is essentially an XOR over the packets' payload (i.e. the packet length is not increased). This rudimentary example serves to show a very relevant point: coding-based transport protocols do not have to acknowledge specific packets. They just need to recover enough coded packets to be able to decode the original data. Each transmitted packet can be created such that it always contains new information to the receiver, which means that no transmission is wasted from a goodput perspective. This contrasts with ARQ-based protocols such as TCP and QUIC, which depend on knowing exactly which packets were lost and false positives can trigger a redundant retransmission, wasting precious bandwidth.
We already have two benefits in the bag: we got rid of a strict dependency on acknowledgments (we need them, but not to know what to transmit next) and we got packet recovery “for free” (any packet can be used to recover the original data). But can network coding also help in distinguishing random losses from network congestion?
Well, it enables a different way to look at losses. Instead of thinking about losses of individual packets as signs of congestion, we may look at how much information is passing through the channel (you can think of it as measuring the goodput of information that reaches the receiver when compared with the throughput generated by the sender).
In Bolina, if a loss is detected but the difference between sending throughput and receiving goodput remains within the expected, then these losses are treated as normal transmission errors. Only if these losses bear an impact in terms of effective goodput will Bolina assume the network is congested. You shouldn’t be tricked into thinking that Bolina only uses goodput to perform congestion control: it uses RTT and jitter signals to help detect congestion. After all, we do not want latency to skyrocket!
Revisiting our benchmark
It is relevant to note that ngtcp2, picoquic and mvfst were using newreno (the congestion control suggested by the current QUIC draft) and the boost.asio client was using TCP Cubic (default TCP version of the operating system). The full setup is described at the end of this post.
For instance, for the 250Kbytes request QUIC always improved with respect to TCP. Gains came mostly from the 0-RTT feature, since this is a request that can be served within a few RTTs.
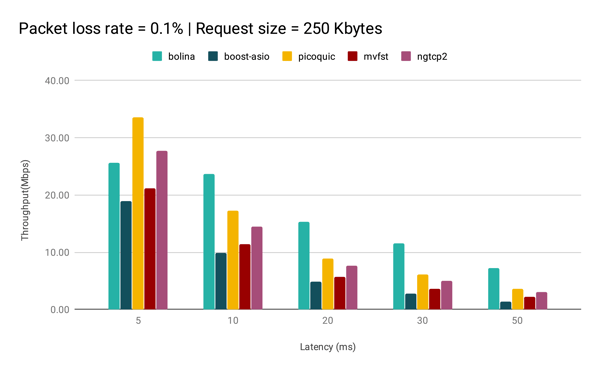
However, with the increase of latency we can also observe that QUIC’s performance decays more than Bolina. This is a consequence of the added RTTs needed to serve retransmissions of lost packets.
Take a look at the largest request. In this case, the congestion control clearly has time to operate and 0-RTT has limited benefit. So, what happened?
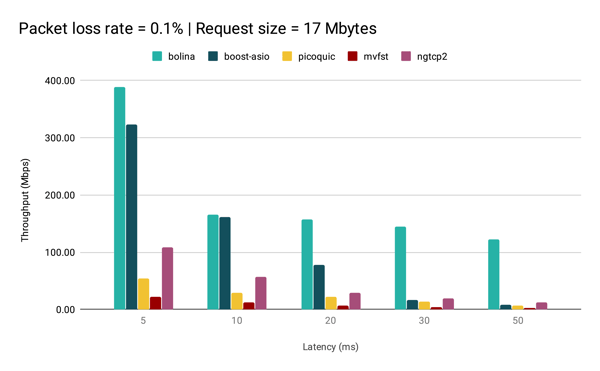
The difference between TCP and QUIC can be explained by the fact that TCP Cubic is much more aggressive on the slow start phase and since, due to packet losses, we spend much time in the slow start phase, it has an “unfair” advantage. However, this difference goes to show the point that congestion control really matters.
It also does not help that QUIC is implemented over UDP. TCP has gone through years of optimization at the hardware level (zero-copy transmit, segment offloading, ...), unlike UDP. Therefore, a protocol functioning over UDP must ensure that its improvements can cover the gap in terms of lower-level performance. That is why Bolina tries to infer if conditions are gathered for UDP to outperform TCP, selecting TCP if it performs better than UDP. It’s actually the reason why Bolina is outperformed by QUIC for the smallest latency point: it has an overhead for searching for the best transport layer mechanism.
Finally, we can also see that Bolina is hardly affected by latency, even under packet loss. For Bolina packet loss does not necessarily mean congestion. For this case in particular, the network was not congested at all. Consequently, Bolina was able to make a much better use of the available bandwidth. Furthermore, the fact that Bolina has inherent loss recovery, ensures that it does not spend an excessive amount of RTTs sending retransmissions.
The past, the present and the future
QUIC has been heavily inspired by TCP’s design. It makes sense, TCP is a robust protocol. However, we’ve all known for a while that TCP deals very poorly with packet loss:
- It has a deficient loss detection mechanism for modern networks.
- It treats transmission errors and congestion-related losses the same way, unnecessarily reducing it’s throughput.
QUIC definitely showed a leap forward with respect to TCP:
- it has a simpler loss detection mechanism that is less error-prone and more efficient with respect to spurious retransmissions.
While QUIC failed to revisit some underlying TCP design choices and mechanisms, the good news is that QUIC is greatly engineered and was designed in such a way that it can easily evolve over the years. In particular, QUIC allows:
- new congestion control algorithms to be easily implemented;
- adapting loss detection variables to network environments (to further optimize loss detection)
- smart feedback schemes based on the ability of the sender to control the acknowledgment generation process (less chatty protocols)
The bad news is that QUIC will still work in an ARQ world... And while it could minimize some of ARQ’s inefficiencies, it will not solve them at its core.
Built on top of network coding technology, Bolina offers a completely different perspective on transport protocols where loss is no longer king, but rather link capacity. This is what the transport layer needs: a protocol that does not care how volatile the network underneath is, making a more efficient use of the available bandwidth. Ready to try it out? Start now.

Code and benchmark details
I started this blogpost with the intent of analyzing the performance of QUIC over channels with latency and packet loss. To do this, we’ve chosen three QUIC implementations: (ngtcp2, picoquic and mvfst through proxygen). We tested draft-20. All of them contain simple implementations of a QUIC client and QUIC server that we used to measure throughput. If you want to test QUIC by yourself, we have a project on GitHub that you can access here.
Our initial goal was to test these QUIC libraries in a mobile environment, but none of them has mobile support. Thus, we had to perform the tests in a desktop environment, which in turn took us to build a Bolina Client for a desktop environment solely for the purpose of this test.
Bolina Client is publicly available for Android and iOS and we’re working on building a QUIC SDK for mobile environment as well. In the meantime, in case you want to replicate the above results, please contact us to get the necessary Bolina Client binaries for Desktop. In case you are curious about Bolina's application, we have two use-cases (video streaming and social networks) available here.
All tests were performed using HTTPS with Let’sEncrypt certificates generated through certbot.
With respect to the client and server machines, these had the following specs:
- 4 vCPUs
- 8GB RAM
They were connected through a submillisecond link (~0.5ms) with 2Gbps bandwidth.
To induce latency and packet loss, we used a tc based emulator, you can find it here.




