
TLDR: Recent results by Uber show that, for mobile apps, latency is high everywhere across the globe, killing user experience even in regions like the US and Europe. If you’re thinking you don’t have this problem, you’re wrong. In this post, I’ll show why you probably haven’t yet noticed that you have latency issues in your mobile app, why what you’re doing is not enough, and what can be done to overcome latency.
When reading Uber’s post on their experience with QUIC, what really caught my attention was another confirmation that wireless links are killing mobile users experience, globally: Uber experiences high latency globally, including in the US and in Europe.
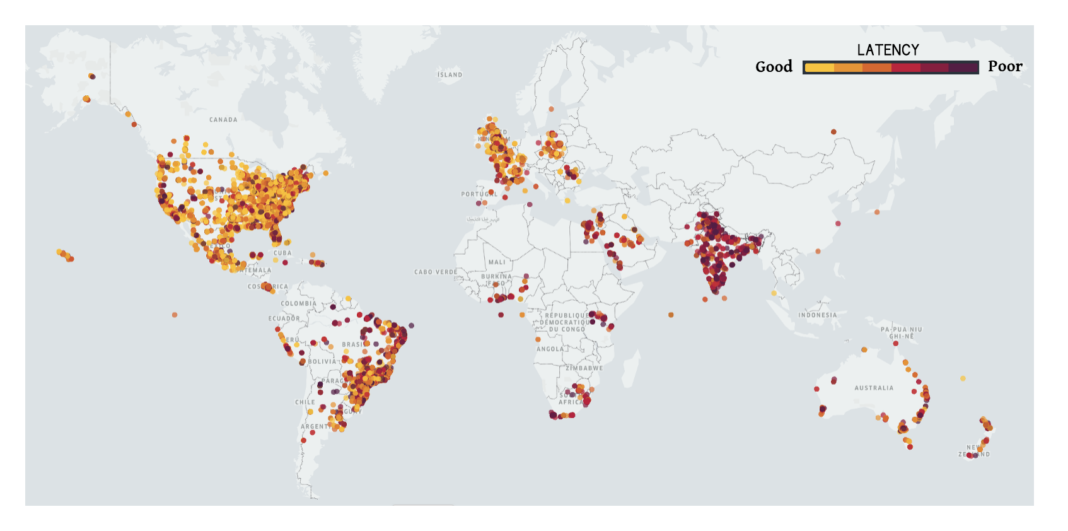
Tail-end latencies experienced in the Uber mobile app (source)
Were you surprised or shocked by the above latency results? I know that if you use CDNs and/or have your user base in regions where the network is excellent, you probably think you don’t have a latency problem. However, I am sorry to tell you: that's not exactly true. My guess is that you’re caught by the average latency trap. Summarizing: average latency tells you nothing about your end users experience, tail-end latency is what dominates user experience. To be clear, by tail-end I mean the high percentiles (95%, 99%, 99.9999% percentiles).
Why is it the tail-end of latency that matters? Quoting Gil Tene, “because humans do not perceive the commonplace; they do not forgive you because your average is good… pain and bad experience is what you remember”. This is Gil’s romantic summary, but he has a lot more to say: I strongly recommend his "How NOT to Measure Latency" talk (written version here).
Before going into the details, let me first tease you:
- On the simplistic Google search page, 25% of the clicks will experience 95%’ile latencies
- 99% of users experience ~99.995%’ile response times
Yes, that’s right! And it’s actually quite simple to understand the basics: latency data is collected on a per-request basis, while loading a page consists of multiple HTTP requests. In essence, it is the slowest of those requests that will dictate user experience.
Doing some math (details in Gil’s talk) and looking at some popular pages, we get the following table:
| Website | # of requests | Page loads that experience the 99%’ile |
| amazon.com | 190 | 85.2% |
| nytimes.com | 173 | 82.4% |
| twitter.com | 87 | 58.3% |
| facebook.com | 178 | 83.5% |
| google.com | 31 | 26.7% |
I’m sure that now it became clear why is Uber looking at tail-end latencies. The next question is then “why on Earth is latency so high everywhere?” Actually, it’s much worse than that: even in the same location, latency and, consequently, your end user experience is highly volatile. Taking another dip from the aforementioned Uber’s post:
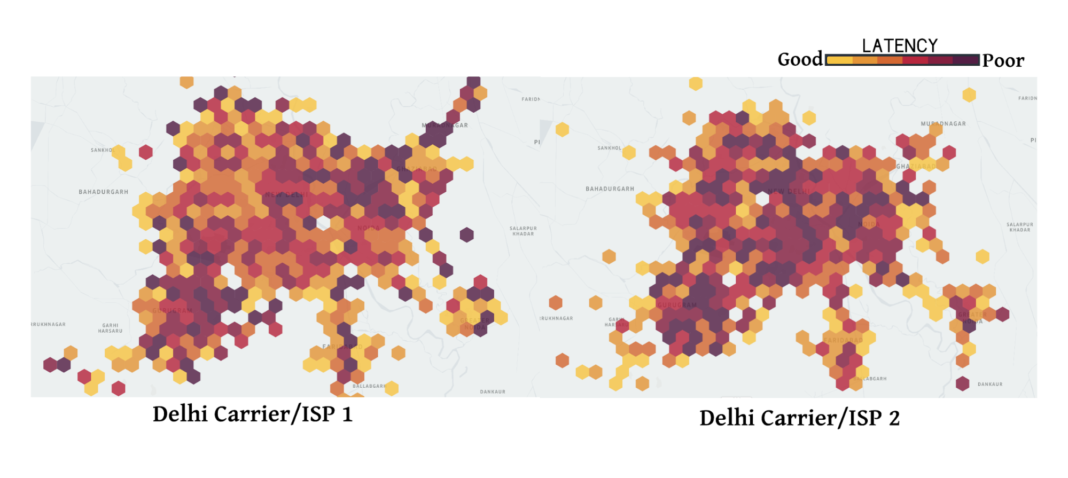
Tail-end latencies in the same areas for two different carriers in Delhi, India, for the Uber mobile app. (source)
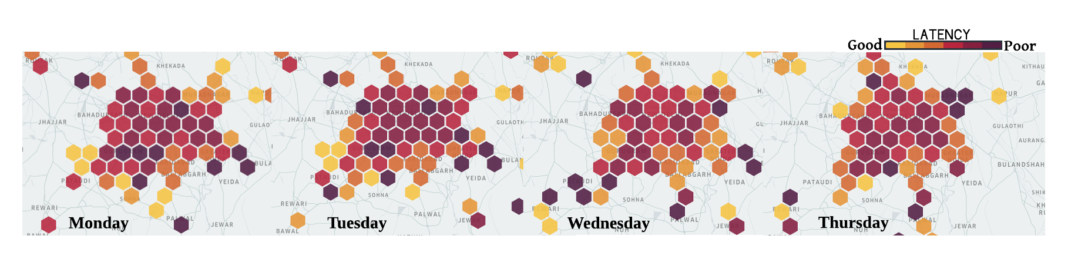
Tail-end latencies in the same areas, on the same carrier, from day to day, on the same carrier, for the Uber mobile app. (source)
In a nutshell, latency dramatically varies with area, carrier or even the day of the week.
Why do we see this latency behavior, even with CDNs everywhere and carriers investing more and more in infrastructure? Placing content closer to the end users, a.k.a. using a CDN, does decrease the latency, but it doesn’t solve this dramatically poor and unstable behavior. For example, Uber went a step further in their testing, by using TCP Points-of-Presence (PoPs) closer to the users, looking for the potential reduction of RTT and faster adaptation to lossy links. However, their results showed no significant improvement by using the TCP PoPs, proving that the bulk of the RTT and losses was coming from the wireless link.
So, what’s the root for this globally poor latency behavior? The answer is simple: wireless communication is highly dynamic and lossy, and HTTP/TCP handles very poorly with that instability.
Irrespective of the technology (WiFi, 3G, 4G or even the upcoming 5G), wireless is a shared medium, which is subject to losses due to interference and signal attenuation, among others. This leads wireless communication into having significantly higher packet loss and round-trip times (RTT) than the wired case. And why are packet loss and RTT so important for end-user experience? Because they kill speed.
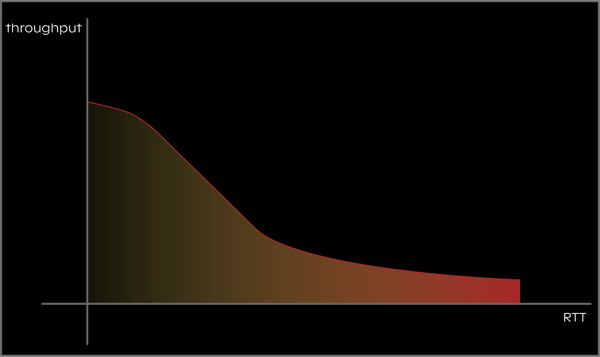
Leaving the details for our technology page, I’ll just share with you a simple example: if the link loses 0.1% of the data packets, HTTP speed goes down by 5 times. And this is quite frequent in a wireless link.
The numbers on packet loss and RTT shown in the aforementioned Uber’s post are quite impressive, which take us to question the (quoting) “common notion that cellular networks’ advanced retransmission schemes significantly reduce losses at the transport layer.” Looking at the data from the paper “Mobile Network Performance from User Devices: A Longitudinal, Multidimensional Analysis”, we can see a few other examples of how severe is this wireless instability. For example, look at how RTT varies across carriers and access technologies.
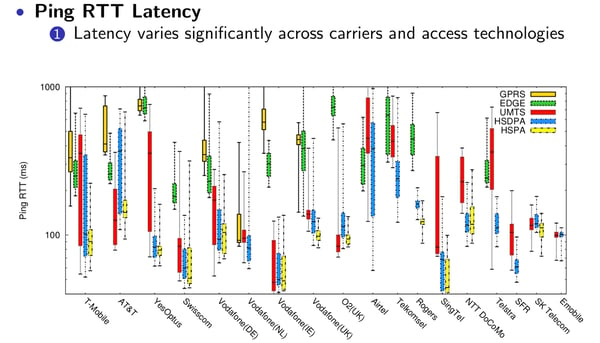
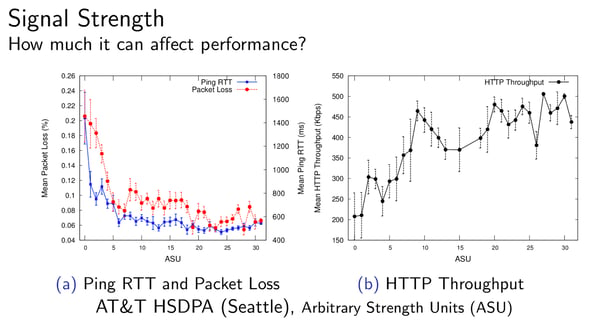
Noticed that the y-axis goes up to 1 second? Now, look at how the signal strength affects RTT and losses:
Another interesting analysis was provided by Viscarious in the League of Legends blog, where the author compared the gaming experience between Ethernet and WiFi. The results show that WiFi increases RTT by a value between 6.7ms and 11.7ms, and packet loss increases in WiFi by a value between 1.9 and 3.7 percentage points. As a curiosity, the results also show that in some cases, players on Ethernet have a slightly higher chance of winning when compared with the players on WiFi.
Fundamentally, this means that we’re using a communication protocol that is highly sensitive to link quality fluctuations, over networks that are highly unstable and, maybe worse, highly unpredictable. I believe that now it became clear why you shouldn’t be surprised to see high latency and, consequently, user experience problems all over the globe.
So now the question is: what can we do? Picking up from the previous paragraph, wireless networks are highly unstable, but that’s intrinsic to the nature of the wireless medium. So we’re left with optimizing the communication protocol.
That’s precisely what internet giants like Google, Facebook, Uber and Cloudflare, among others, are doing, with their efforts around QUIC, and what we’re doing at Codavel with Bolina. QUIC is a valuable Google initiative for a new internet transport protocol, with the ultimate goal of reducing latency, and the first results are interesting. For example, in the aforementioned Uber experiments with QUIC, they were able to achieve above 10% reduction in latency’s 95%-percentile in most cases, and above 15% reduction in the 99%-percentile.
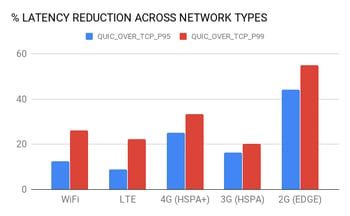
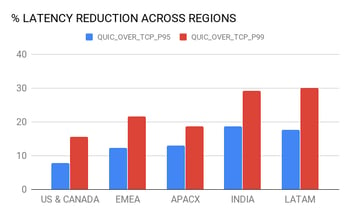
Uber’s production results with QUIC in different geographies, and different network types in Delhi, India (source).
Having said that, although it does achieve latency reduction, QUIC’s impact is marginal, by only optimizing connection establishment but not the actual transport of data. In a previous post of mine, you can find an overview of QUIC with some interesting links where you can learn more about this new protocol.
At Codavel, we’re using a different approach, by entirely revisiting the way data is transported over the internet. Our first benchmark shows that Bolina reduces latency much further than QUIC. We’ll share more data in the upcoming weeks, but if you’re anxious to see it for yourself, you can quickly try Bolina for free!
P.S. In case you’re still wondering why latency is so important, I’ll leave you with a few references. Jeremy Wagner has compiled a comprehensive list of case studies on how network performance impacts business performance. WPO Stats also has a comprehensive list of case studies and experiments demonstrating the impact of web performance optimization on user experience and business metrics. Also, for their different approach, I enjoyed reading LinkedIn’s analysis on how network quality affects user engagement. Short summary of all that: you must pay attention to the latency experienced in your app.




