
tl;dr: there are a lot of challenges in scaling a cache system, but simple is always better!
What do we want? Content! When do we want it? Now!
We’re in the business of getting content to end users faster than anyone else! We’re very proud of what we’ve accomplished: we developed an awesome transport protocol that provides an amazing user experience to end users, even if they have the worst connection!
However, our search for the best user experience does not end here! We’re always looking for ways to improve performance! As you may have guessed, one of the ways to do this is to place content closer to end users (that’s right, exactly what a CDN does), and that is where caching enters.
Are you talking about the cache I really think you’re talking about?
You’re right! I should be clear about this from the start - there are just so many layers of caching nowadays...
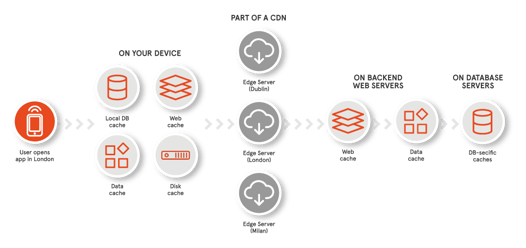
Most apps and services today have users spread around the world. They also have a tone of content to provide to end users (think about an e-commerce website like Amazon and the amount of images it needs to provide to end users searching for a product). So to place the content near your users, you could just have a bunch of data centers around the world with all your content replicated. Everything is great, except now all the money you earned is to pay your data storage bill…
That’s the main reason why you would use a web cache! Instead of having your content needlessly replicated in all your data centers, you can have a few servers storing your content (origin server) and spread web caches around the globe, which would store temporary copies of your content that can be fetched later by the same users or even by other nearby users.
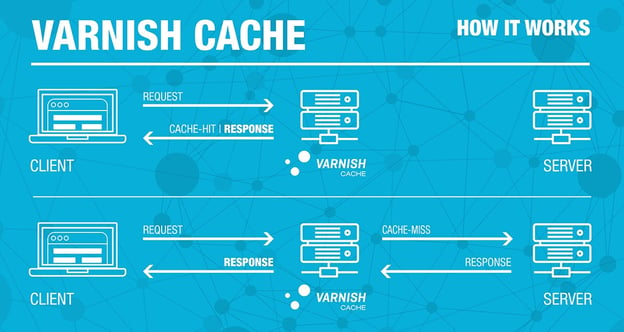
The above picture illustrates this. A client generally makes a request to a web cache (we’ll check in a minute how) and if this cache has the request content it is returned, otherwise it fetches this content from an origin server, possibly stores this content (cache-control headers can prevent caching, for instance) and forwards it back to the client.
What are the benefits this cache brings to the table? First, it reduces load at origin servers, meaning they help dealing with usage spikes, allowing content to be always available. Second, they allow a reduction of traffic, contributing to a reduction in network congestion. And third, they help improve performance by placing content closer to end users. But remember, you only reap these benefits if two things happen: if your cache is closer to your user and if your cache hit ratio (i.e. the percentage of requests that your cache is able to fulfil without going back to the origin) is good enough!
Cool concept, how did you implement this?
Using the most possible simple approach: reverse proxying! For this we used two beautiful tools: Varnish Cache and NGINX.
Our backend architecture is as simple as this: we have a first NGINX acting as a load balancer to multiple Varnish caches, followed by an NGINX that acts as a reverse proxy to origin servers.
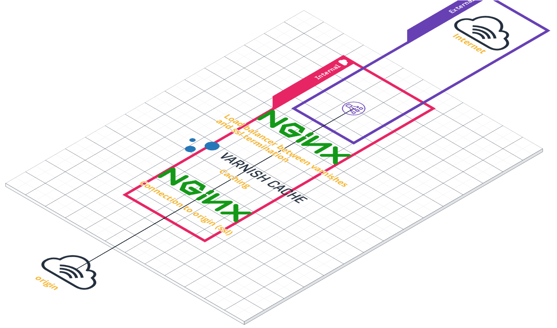
The question that may come to your mind is why do we need NGINX. The first reason is obvious. If we want to scale the number of cache instances you need to have a way to reach them. You may argue that we could have done this with a simple auto-scaling mechanism of cache instances and automatic updates of DNS records or via a regular load balancer... That’s true, but that way we would miss a possible opportunity to optimize our caching strategies by making use of NGINX capabilities. So we use NGINX as a “smart” load balancer for our varnish clusters. In addition, using NGINX will allows us to better scale our varnish cluster (we’ll explain it in a bit)
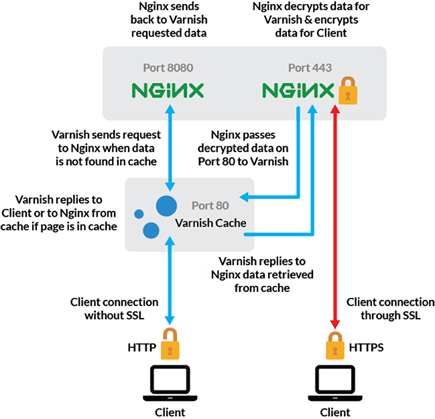
We also need to handle both HTTP and HTTPs requests from end users. Unfortunately Varnish Cache does not support HTTPs (only Varnish Plus). One way to circumvent this is to use NGINX to provide SSL termination in order to be able to also serve cached HTTPs requests. Essentially, the end users talk HTTPs with NGINX, which on the other hand talks HTTP to Varnish Cache. If Varnish Cache needs to go to the origin, it talks again HTTP with an NGINX reverse proxy, which talks HTTPs with the origin server. This was not a strong requirement for us, as our typical deployment has a kind of proxy server sitting between the client and the caching service (which poses additional challenges as we will show later), but this is a common use case for most services.
You may also wonder why we chose Varnish Cache. Aside from the obvious reasons of simplicity, visibility on the metrics that matter and availability, Varnish Cache provides a high degree of flexibility via the Varnish Configuration Language (VCL), allowing us to tune the cache behavior to our needs! Among some of the features we really enjoy configuring are load balancing for backend servers, the ability to add custom headers or the ability to select what to effectively cache.
The icing on the cake is the availability of a ton of useful extensions that probably already implement what you need! All of these features really help you speed up your development cycle.
Sounds simple… Any challenges you want to share?
First things first. We have two constraints to satisfy: ensure a great end-user performance and support an arbitrary number of users. This means that our cache needs to be able to scale well. As you can guess, the higher the number of requests a cache (or any server) is handling, the more time it will take to satisfy these requests.
Here’s the first decision point: perform horizontal scaling (i.e. more machines) or vertical scaling (increase specs of existing machine)? We decided for horizontal scaling. Why? For our particular case, the biggest point was that by scaling horizontally we had the redundancy we needed to handle any usage spikes or failing nodes.
The second decision point was the natural consequence… What platform will we use to scale? The decision eventually fell on Kubernetes, mostly due to the fact that it allowed us deployment flexibility (bare-metal or cloud-server) and self-healing containers (as well as a nice metrics API). And fortunately for us, NGINX has an ingress controller for Kubernetes!
So we had our setup more or less ready from an architectural point of view! We had our scaling mechanism designed (availability and load ✅ ), we could talk HTTP and HTTPs (http protocols ✅ ), the only thing missing was checking if the performance was what we expected!
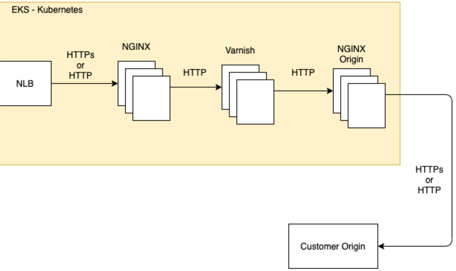
Before going for any type of optimizations we laid down our basic architecture again. We had an NGINX ingress controller to perform load balancing to our varnish cluster (scaled via kubernetes), which if necessary used an NGINX reverse proxy to fetch content from the origin servers. So far so good.
Now thinking about performance… What we want is that our cache tries to fulfill the end users requests and avoid reaching out to the origin server. This would add both a latency penalty to serve the request and increase the network traffic required to satisfy this request (in addition to increasing the load to the origin server). That is, we need to ensure that our cache hit ratio is as high as possible.
What is the challenge here? First of all, we have an arbitrary number of cache nodes in our cache cluster. This means that multiple users can be hitting different cache servers, which could potentially enable multiple requests to the origin, even if the request is the same (e.g. a load balancer using a round robin selector would send sequential request to different servers even if the request is for the same resource).
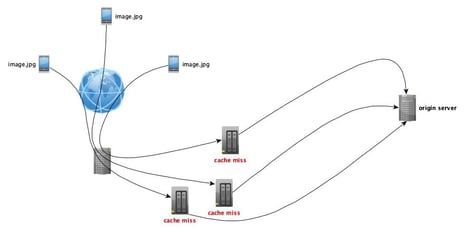
This can be partially solved by using the NGINX ingress controller upstream hashing mechanism. For instance, if you use the request URI as your upstream hashing key, then requests for the same resources will be served by the same cache node. NGINX also allows you to create a subset of nodes into which the hash will be mapped, allowing you to have some control over load and redundancy of your cache servers (at the cost of possibly making some more requests to the origin).
For instance, the following configuration for the Kubernetes ingress controller would use the request URI to redirect the request to a subset of three nodes.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-ingress
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "false"
nginx.ingress.kubernetes.io/force-ssl-redirect: "false"
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/upstream-hash-by: "$request_uri"
nginx.ingress.kubernetes.io/upstream-hash-by-subset: "true"
nginx.ingress.kubernetes.io/upstream-hash-by-subset-size: "3"
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: varnish-service
servicePort: 80
The above approach allows us (via configuration of the ingress controller) to increase the cache-hit ratio. However, the above issue is not the only one caused by scaling mechanisms. More precisely, when using auto-scaling mechanisms it is very common for nodes to be created or tear-down arbitrarily. E.g. if there is a spike of usage and caching nodes become under heavy load, more nodes will be created. When usage goes back to a regular load value, the created nodes (or some other nodes) will be torn down (unused capacity is the more expensive one!).
Why is this a problem? Well, nodes that are teardown may be caching content not cached by any other node. This can reduce your cache hit ratio and eventually force cache nodes to fetch (again) content from the origin server. How can this be avoided? By creating a self-routing sharded cache cluster, where varnish nodes can share their cache. If cache nodes share their cache, when an arbitrary node goes down, there is a high probability that other caching nodes have its content stored, therefore being able to fulfil the requests that would be directed to the node that was torn down, consequently increasing the cache hit ratio!
A very specific challenge…
As far as challenges are concerned, we had one final challenge. If end users talk to a proxy server that uses the deployed cache service, this proxy may be the one doing the client SSL termination (this is actually our main use case!).
This proxy server talks regular HTTP with the ingress controller, so how can we ensure that when the client is using HTTPs, the cache service can talk HTTPs with the origin server? Luckily, NGINX can come to the rescue! Remember how varnish nodes talk to a reverse proxy when needing to reach the origin server? This setup made our problem much simpler. Essentially, the only thing we needed to do was to make a proxy server to add a specific header that tells NGINX what protocol to use: HTTP or HTTPs. The bellow configuration is an example that allows you to do just that!
http {
tcp_nodelay on;
map $http_secure $origin_scheme {
default "http";
true "https";
}
server {
listen 27003 default_server;
location / {
resolver 8.8.8.8;
proxy_pass $origin_scheme://$host;
proxy_ssl_server_name on;
proxy_set_header Host $host;
proxy_ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
proxy_ssl_ciphers HIGH:!aNULL:!MD5;
proxy_ssl_session_reuse on;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
}
What could be a hairy problem, turned out to be quite simple due to the features offered by the components we used.
And that’s it!
We tried to show you how we deployed a scalable caching mechanism, where performance, high availability and efficiency were at the core of the decisions process.
When laying down your architecture, it’s really important you think about what you need to optimize, how the system will behave in terms of node availability and its impact on performance.
The pieces you choose to assemble the caching system are also very relevant and can make the deployment process very simple, rather than a nightmare.
Oh! I almost forgot, that’s what the deployment we’ll look like when you’re done!
.png?width=402&name=unnamed%20(1).png)




